A Gaming Company Just Won the Voice Quality Crown
Here's a result that should make every TTS giant uncomfortable: Inworld AI, a company best known for powering NPC dialogue in video games, just took the #1 spot on the Artificial Analysis Speech Arena with an ELO of 1,162. That's ahead of ElevenLabs. Ahead of OpenAI. Ahead of everyone.
Their secret? Dynamic range. While most TTS models optimize for a pleasant, consistent narration voice, Inworld's TTS-1.5 Max handles the extremes — whispers, shouts, emotional breaks — with significantly less distortion than the competition. That's exactly what you need for games where an NPC might go from a hushed conspiracy to a battle cry in the same sentence.
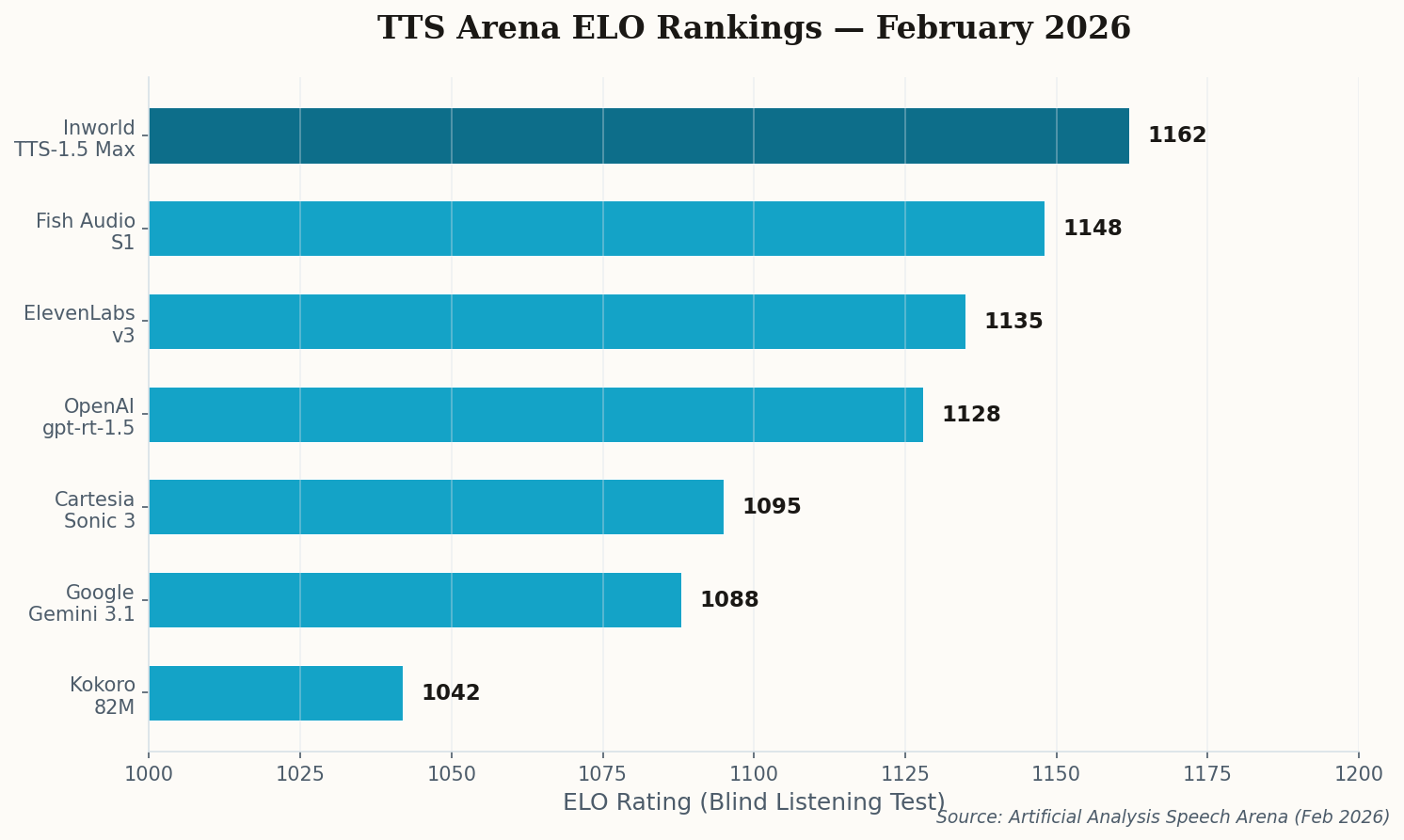
The lesson here is counterintuitive: the best general-purpose voice came from a company solving a niche problem. When you optimize for the hardest use case — procedurally generated dialogue that needs to sound natural across every emotional register — everything else becomes trivially easy. The "digital sheen" that plagues high-compression models? Gone. Inworld solved it because gamers would never tolerate it.