Running Llama 4 Maverick on Your Desk Is No Longer a Fever Dream
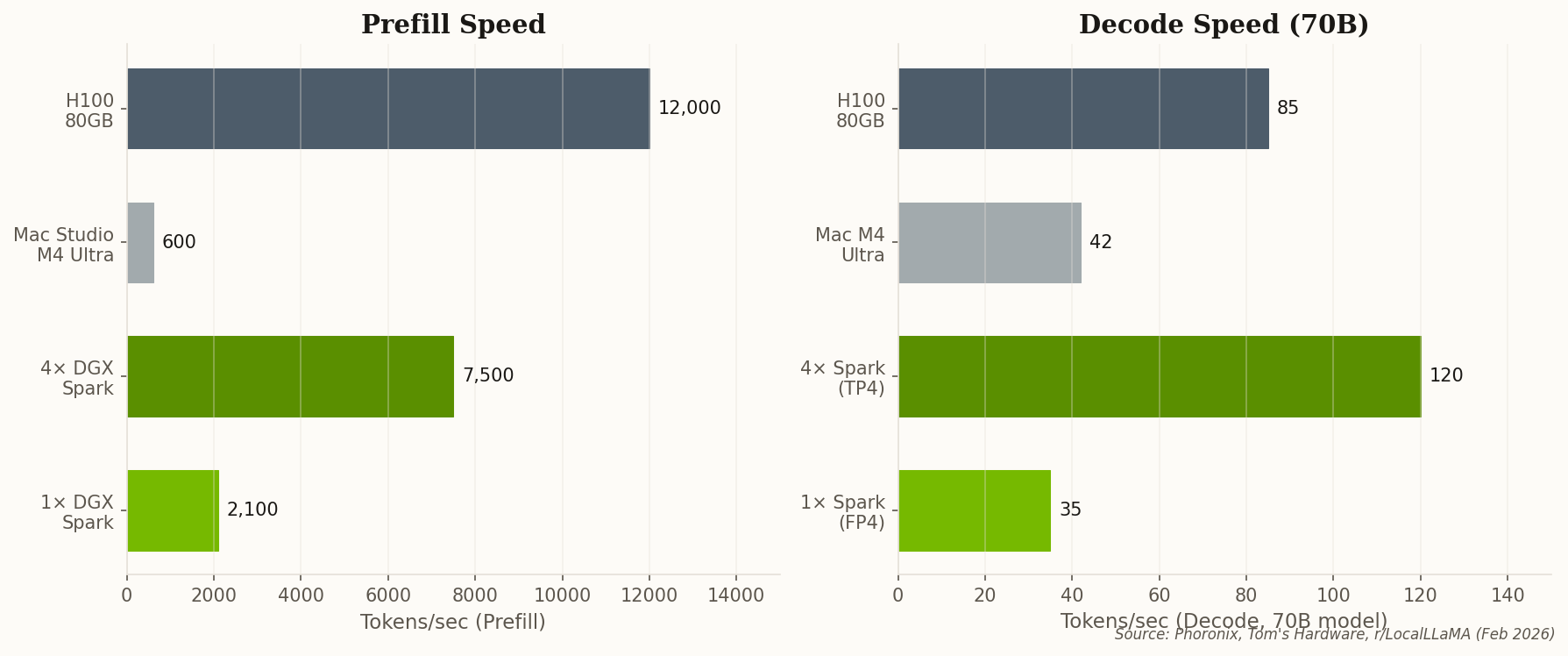
Here's the number that should keep cloud providers up at night: 5–8 tokens per second on a 400-billion-parameter model, running entirely on hardware you own. The r/LocalLLaMA community has been putting four-node DGX Spark clusters through their paces, and the results are quietly stunning.
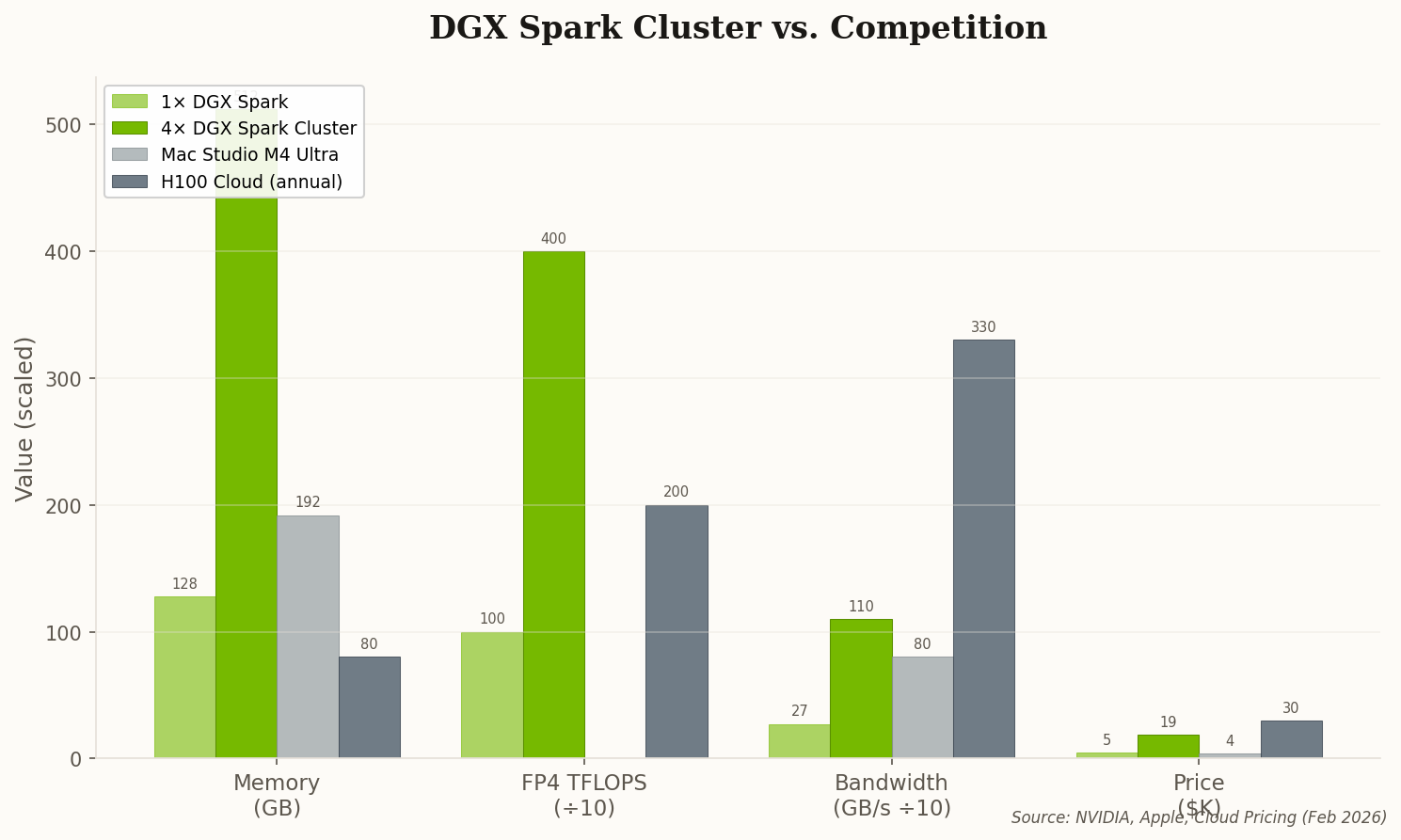
Llama 4 Maverick, Meta's 400B flagship, runs with full context on the 512GB memory pool. No quantization hacks, no offloading gymnastics—the model just fits. DeepSeek-V3, with its mixture-of-experts architecture, hits ~12 tokens/sec by keeping hot experts in GPU memory and cold ones in CPU territory. That's faster than most people type.
But the real flex is context length. Users report running 128k context windows on 70B models without noticeable degradation. For researchers doing long-document analysis, RAG pipelines, or multi-turn reasoning chains, that's the difference between "proof of concept" and "production-grade." One commenter nailed it: "Running a 400B model locally without a server rack is a religious experience for an AI researcher."
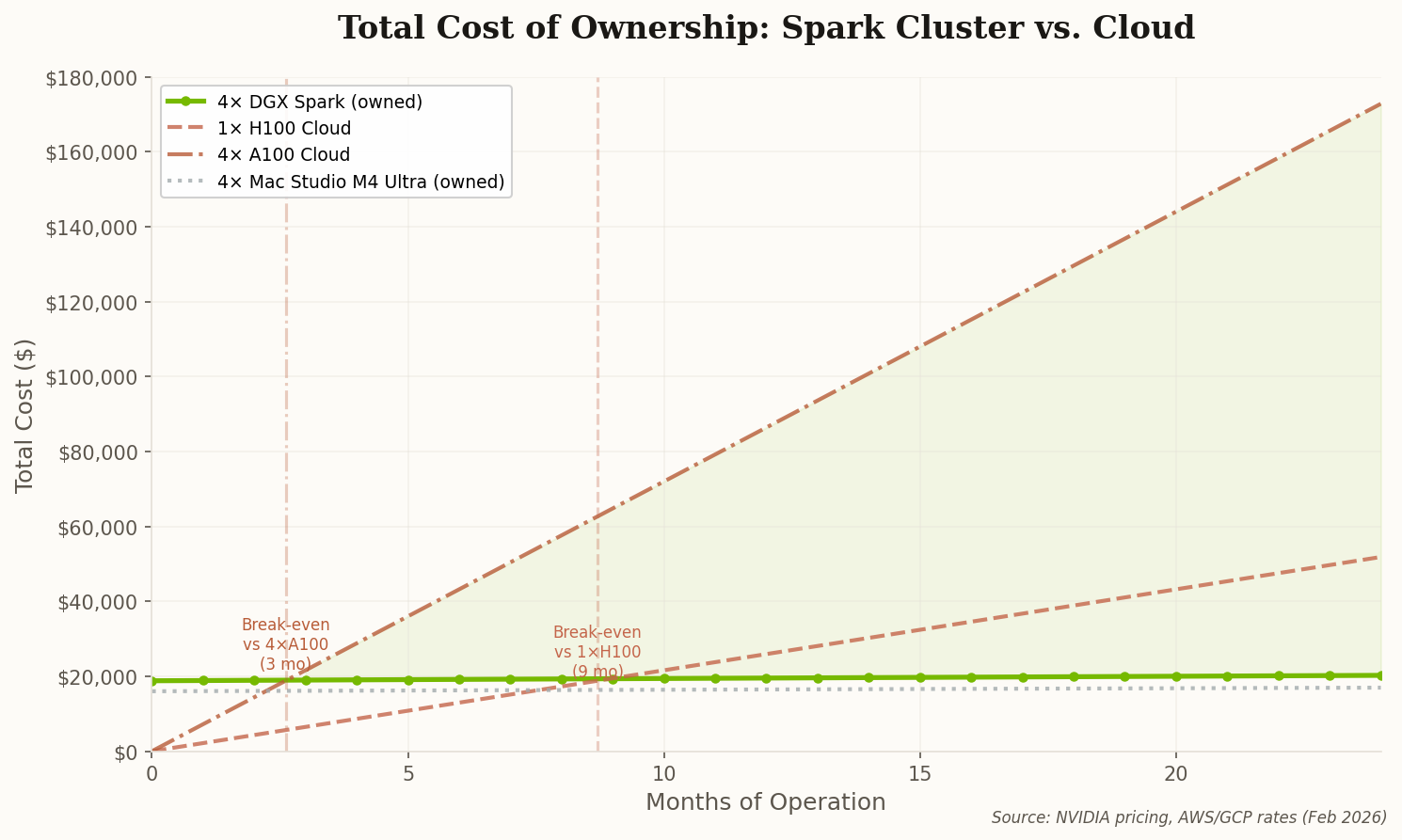
The math is straightforward. A comparable cloud H100 instance runs $3/hour. At 720 hours/month, that's $2,160. The Spark cluster pays for itself in under 9 months—and then it's free forever. That changes the calculus for every university lab and startup team with a tight GPU budget.