NVIDIA Just Made the Mac Studio Look Like a Bargain

The DGX Spark's MSRP just jumped $700 — from $3,999 to $4,699 — and NVIDIA is blaming LPDDR5x supply constraints. That's an 18% price hike that fundamentally reshapes the math for anyone weighing these two platforms.
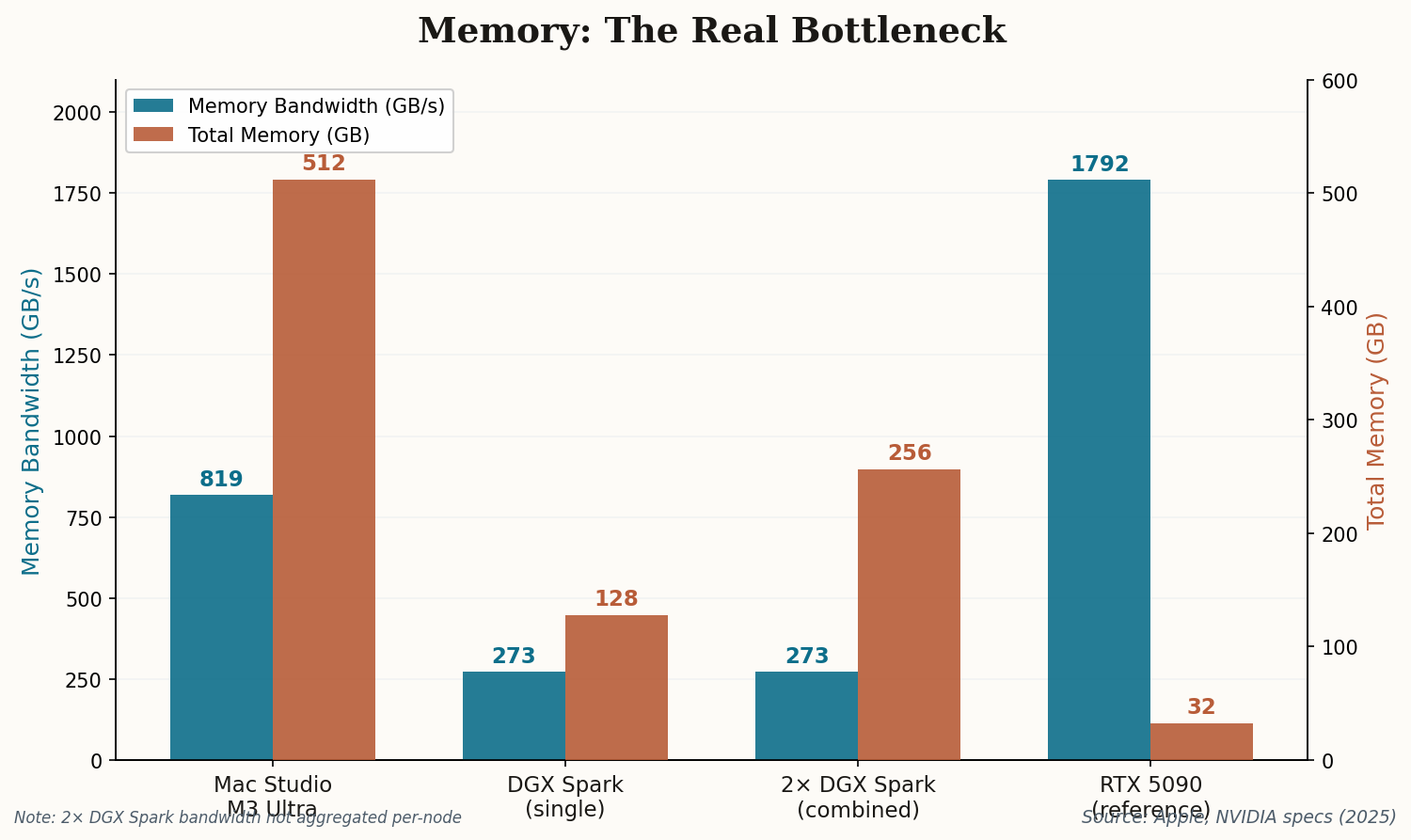
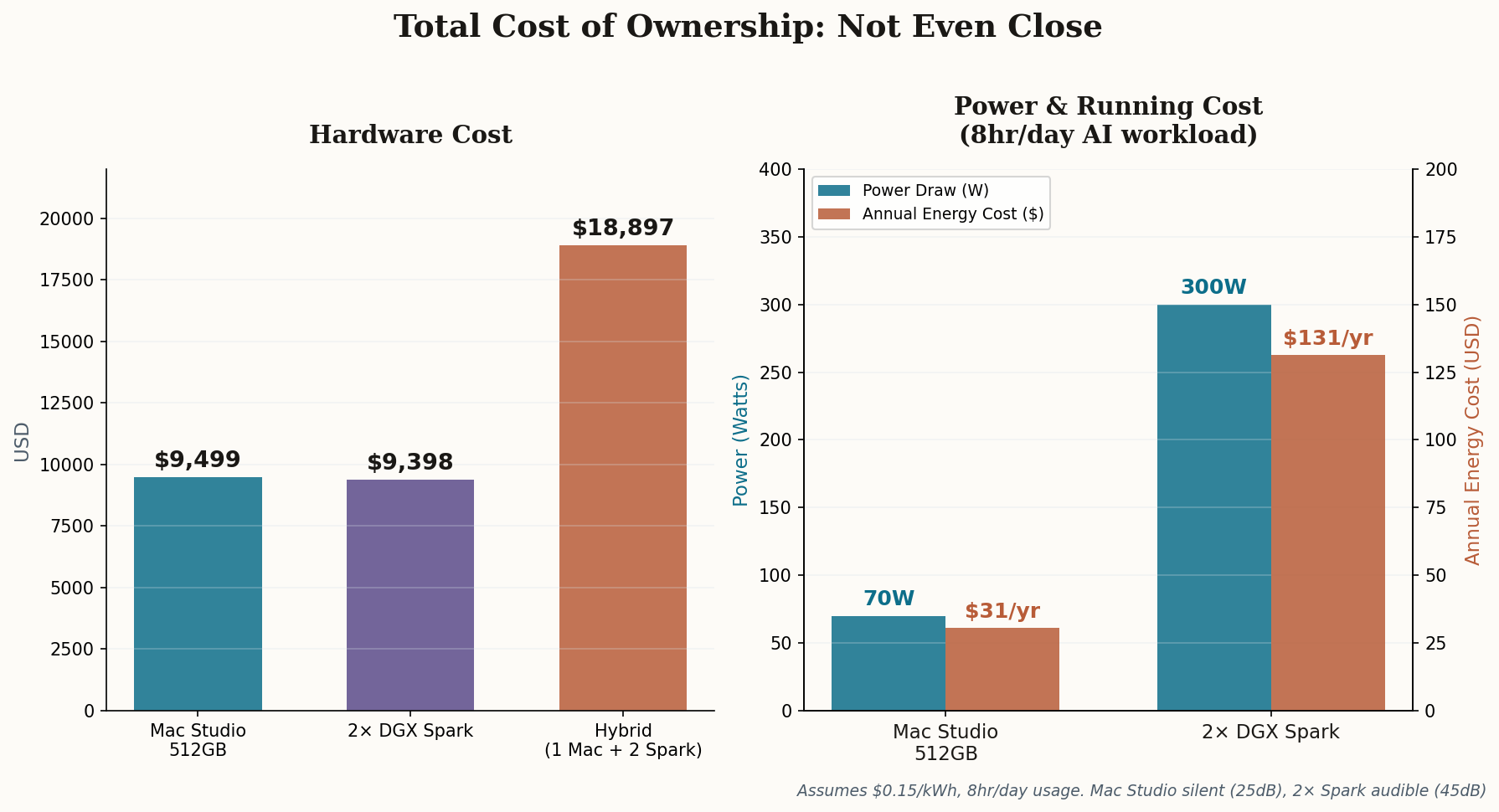
Two DGX Sparks now run $9,398. A Mac Studio M3 Ultra with 512GB unified memory starts at $9,499. We're talking a $101 difference for dramatically different hardware: the Mac gives you 4x the memory (512GB vs. 256GB combined), 3x the bandwidth per node (819 GB/s vs. 273 GB/s), and silence. The Sparks give you roughly 77x the AI compute (2 PFLOPS sparse FP4 vs. 26 TFLOPS FP16) and the entire CUDA ecosystem.
The price parity is almost poetic. NVIDIA positioned the Spark as a "personal AI supercomputer on your desk," but at $4,699, that desk needs deep pockets. For developers whose primary workflow is running coding models — not training them — the value proposition has shifted decisively toward Cupertino.