DeepSeek V4 Is About to Make Your Cloud Bill Look Ridiculous
There's a model launch happening this week that could permanently alter where serious code gets written. DeepSeek V4, expected to drop during China's "Two Sessions" on March 3–4, is the first open-weights model credibly threatening to match Anthropic's Claude Opus on SWE-bench Verified—the benchmark that actually matters for real-world software engineering.
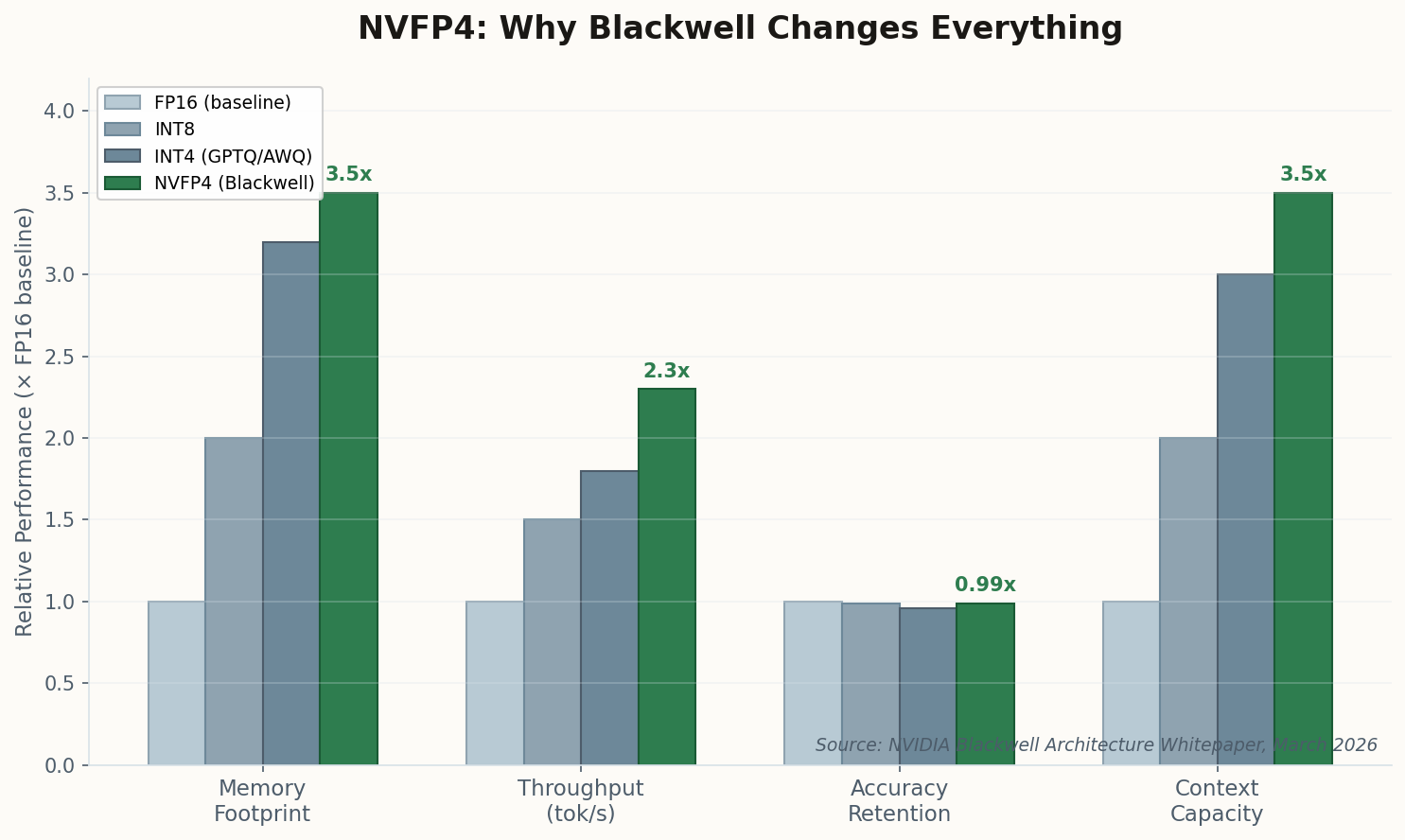
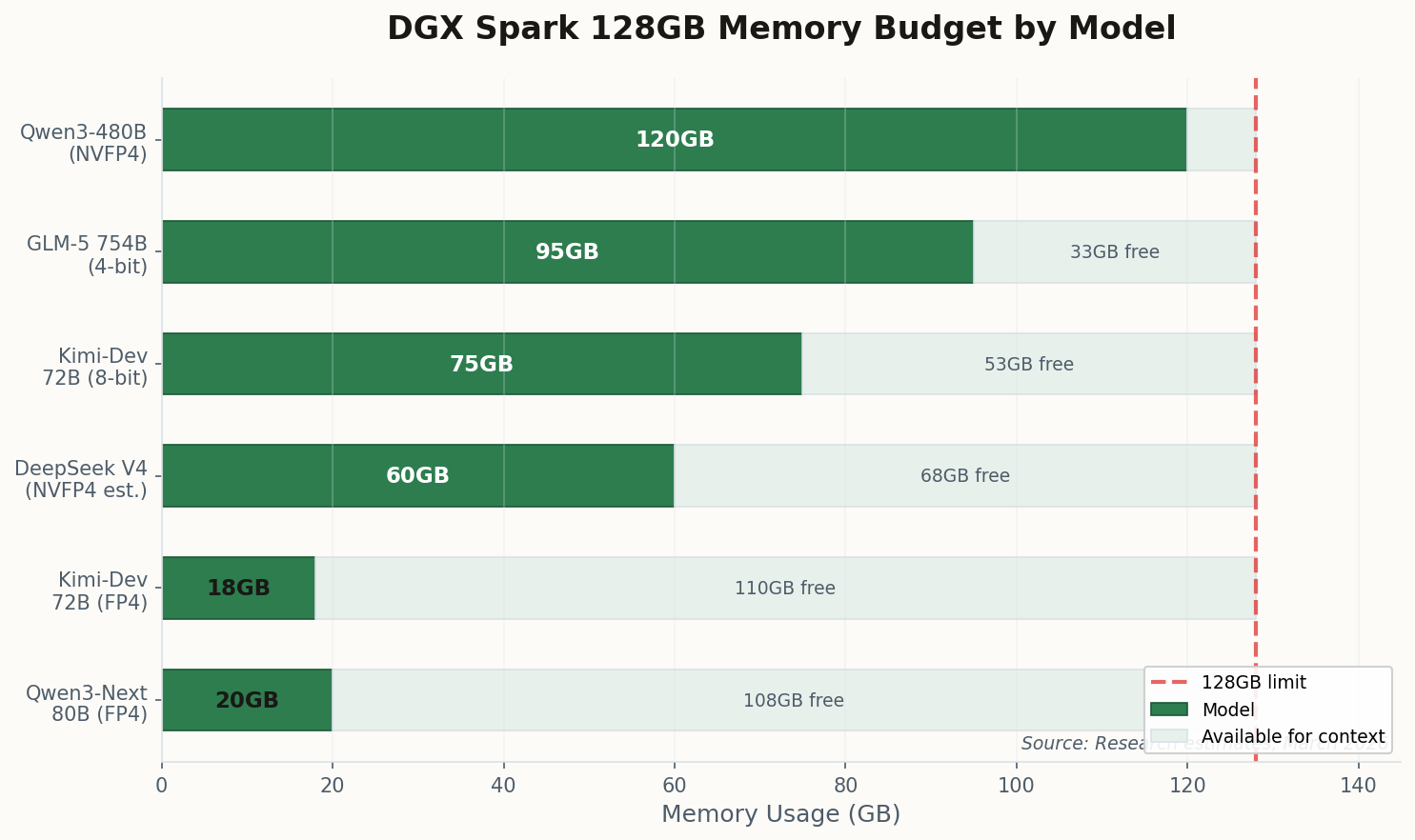
The leaked numbers are staggering: north of 80% on SWE-bench Verified, achieved through a new "Engram Memory Architecture" that enables million-token context without retrieval penalties. But here's the detail that should make every DGX Spark owner sit up: V4 was explicitly optimized for the 128GB unified memory tier. Not as an afterthought. As a design target.
The shift: DeepSeek V4 doesn't just run locally—it was architectured for local. The Engram system treats unified memory as a first-class citizen, not a constraint to work around. For DGX Spark owners, this means cloud-grade autonomous coding agents that never phone home.
The competitive implications are significant. If V4 delivers on these benchmarks under open weights, the economic case for routing code generation through API endpoints starts to crumble for any team with a DGX Spark on the desk. You're looking at potentially infinite inference at a fixed hardware cost of $4,699, versus per-token pricing that compounds with every agentic loop.
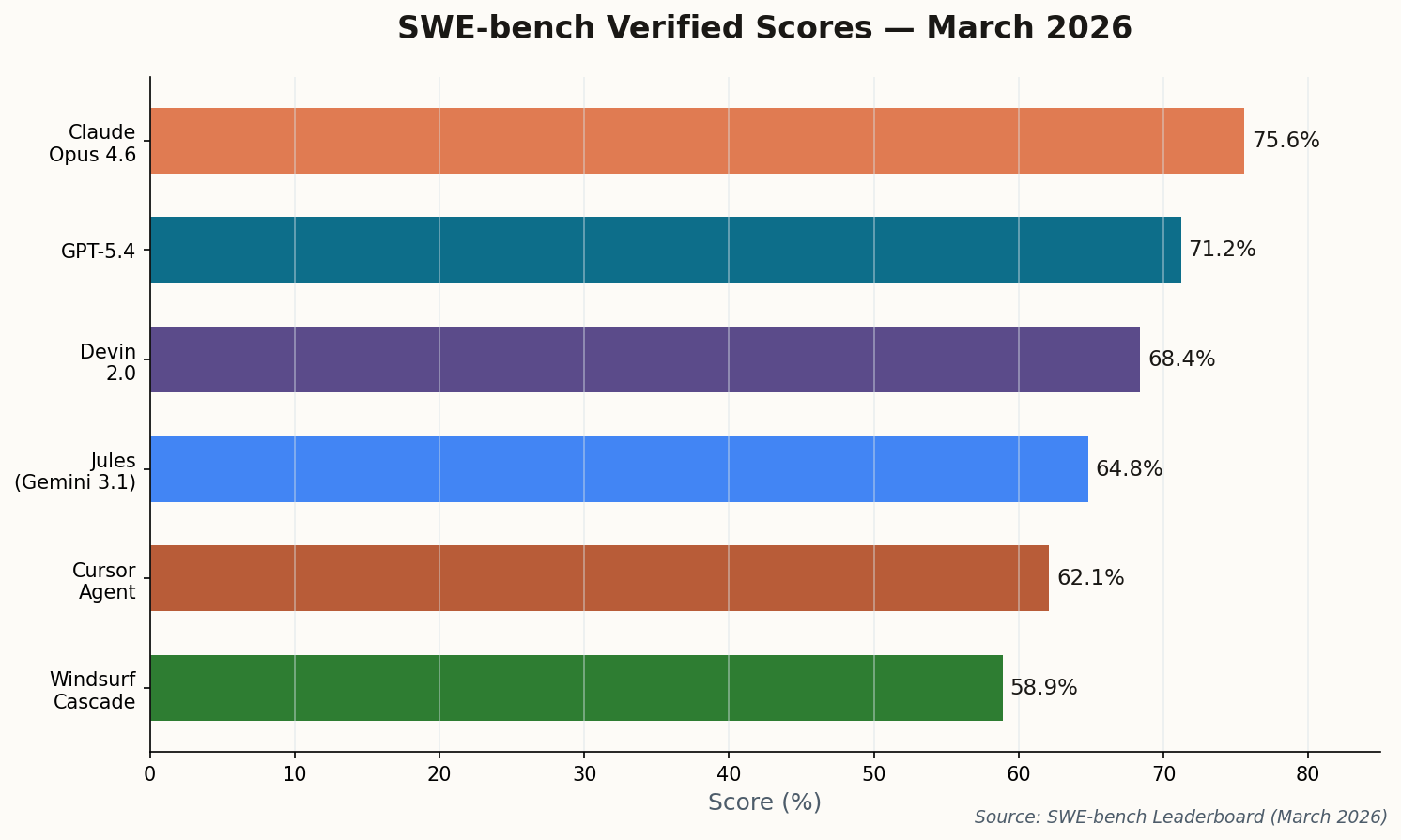
Watch the open-source community this week. If V4's weights land as promised, the DGX Spark instantly becomes the most cost-effective serious coding workstation in existence.