The Industry Just Put a Date on It: GPT-4 Parity by Late 2026
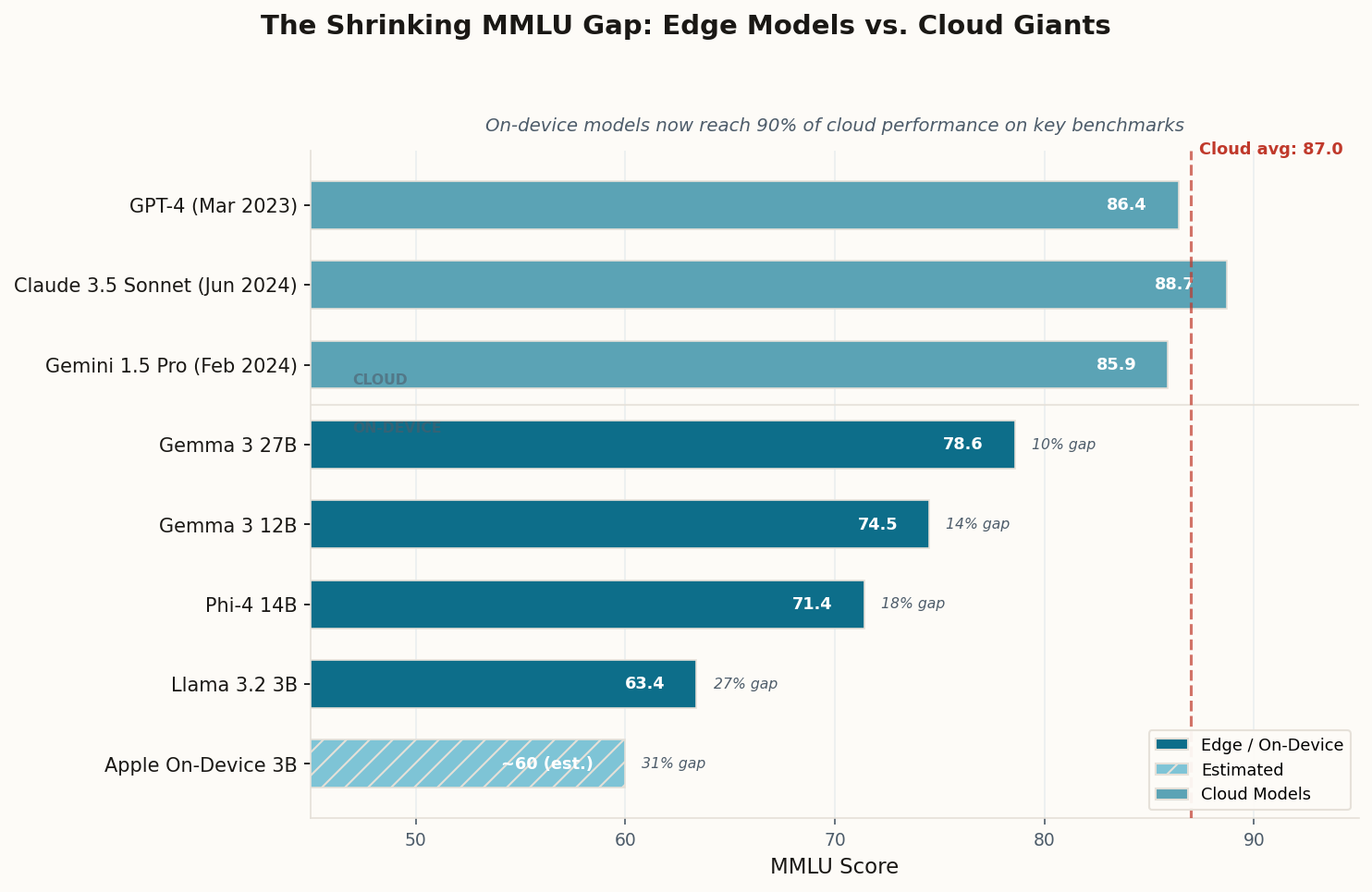
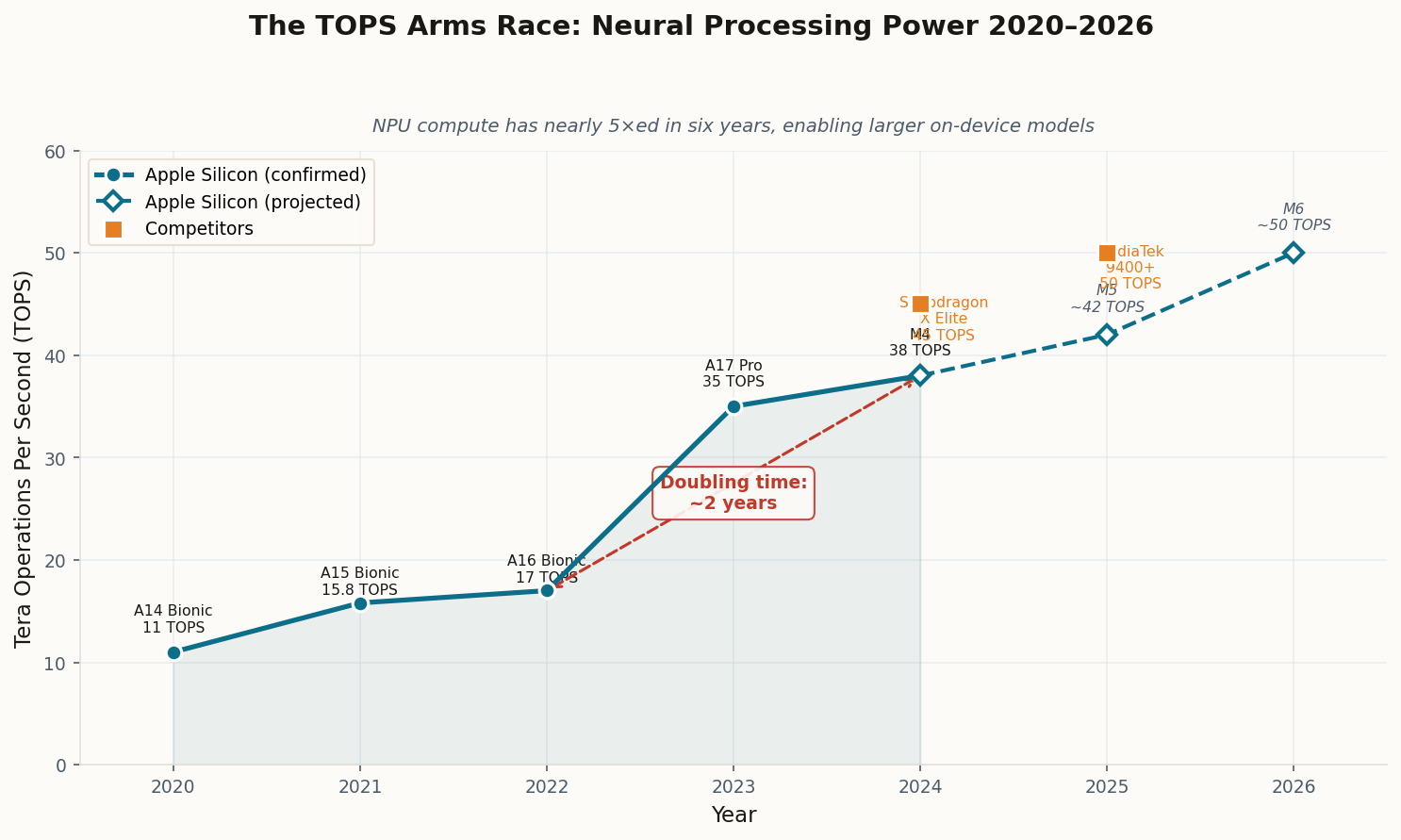
Here's the number that should reshape how you think about your next hardware purchase: industry consensus now points to models in the 3B-to-30B parameter range achieving "GPT-4-class performance on specific tasks" sometime in 2026. Not in a lab. Not on a server rack. On hardware you already own or will buy this year.
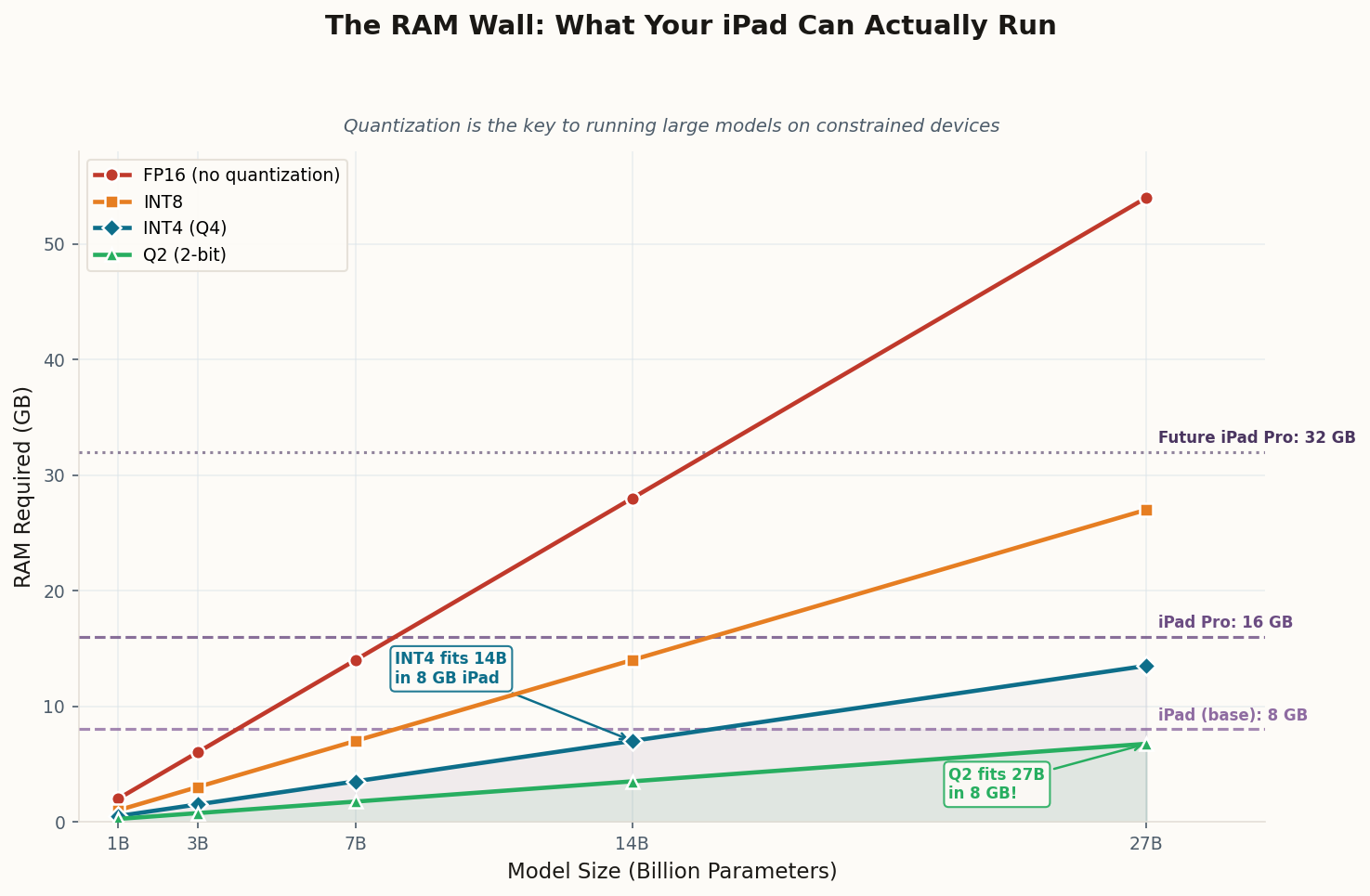
The math behind this isn't wishful thinking. Quantized small language models already retain 70-90% of their full-precision accuracy while consuming 75% less memory. Edge models running at 50 to 500 tokens per second are actively replacing API calls for real-time applications — from live translation to code completion to document summarization. Gartner projects that by 2027, small language models will be used three times more frequently than general-purpose LLMs by organizations.
The critical insight isn't that on-device models will be "as good" as GPT-4 at everything. They won't. The insight is that 90% of the tasks you actually perform — drafting emails, summarizing documents, answering factual questions, writing code snippets — don't require a trillion-parameter model sitting in a data center 800 miles away. A well-tuned 14B model running locally can handle those tasks at the same quality level, with zero latency and complete privacy. The cloud's monopoly on useful intelligence is already cracking.