The Scoreboard Doesn’t Lie: 80.9% vs 76.8%
Twelve months ago, the best open-source model on SWE-bench Verified scored around 55%. The best frontier model cleared 65%. A ten-point chasm that felt structural. Today? Anthropic’s Claude Opus 4.5 holds the crown at 80.9%, with Opus 4.6 a hair behind at 80.8%. But the open-weight upstarts are breathing down their necks: MiniMax’s M2.5 hit 80.2%, Zhipu AI’s GLM-5 reached 77.8%, and Kimi K2.5 scored 76.8%.
The gap between the best closed and best open model has compressed from a yawning canyon to roughly 4 percentage points. And that understates the shift. MiniMax M2.5—an open-weight model with 229 billion parameters—now sits at #3 overall, ahead of OpenAI’s GPT-5.2. Four of the top ten models are Chinese open-source entries. The center of gravity is moving.
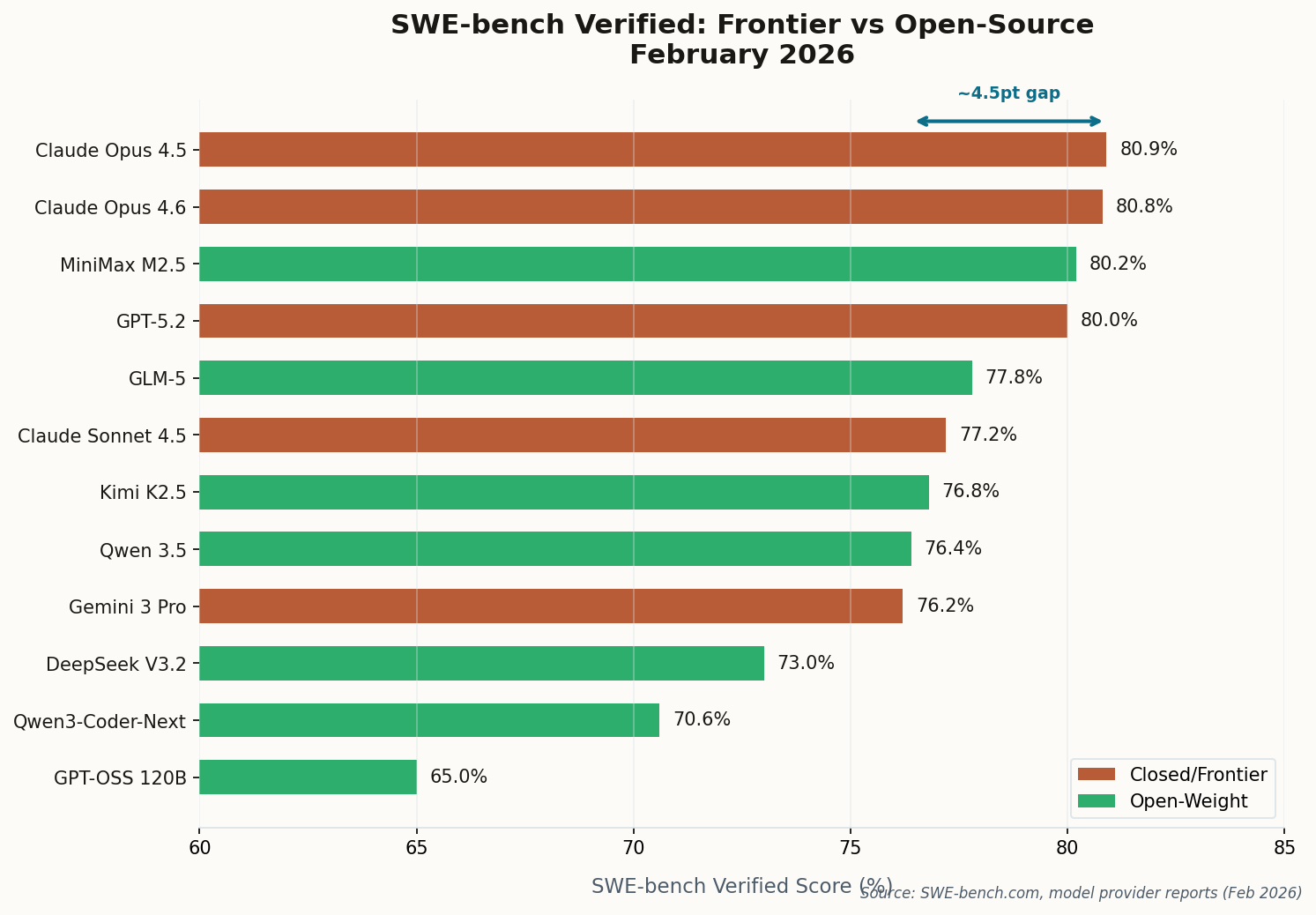
Perhaps the most startling data point comes from a model few people are watching: Qwen3-Coder-Next scored 70.6% on SWE-bench Verified with only 3 billion active parameters. It also beat Claude Opus 4.5 on SecCodeBench for secure code generation by 8.7 points. When a model the size of a rounding error outperforms a $15/million-token frontier model on security, the definition of “gap” needs updating.