The Privacy Pivot Is Real—and Apple Didn't Even Have to Ask
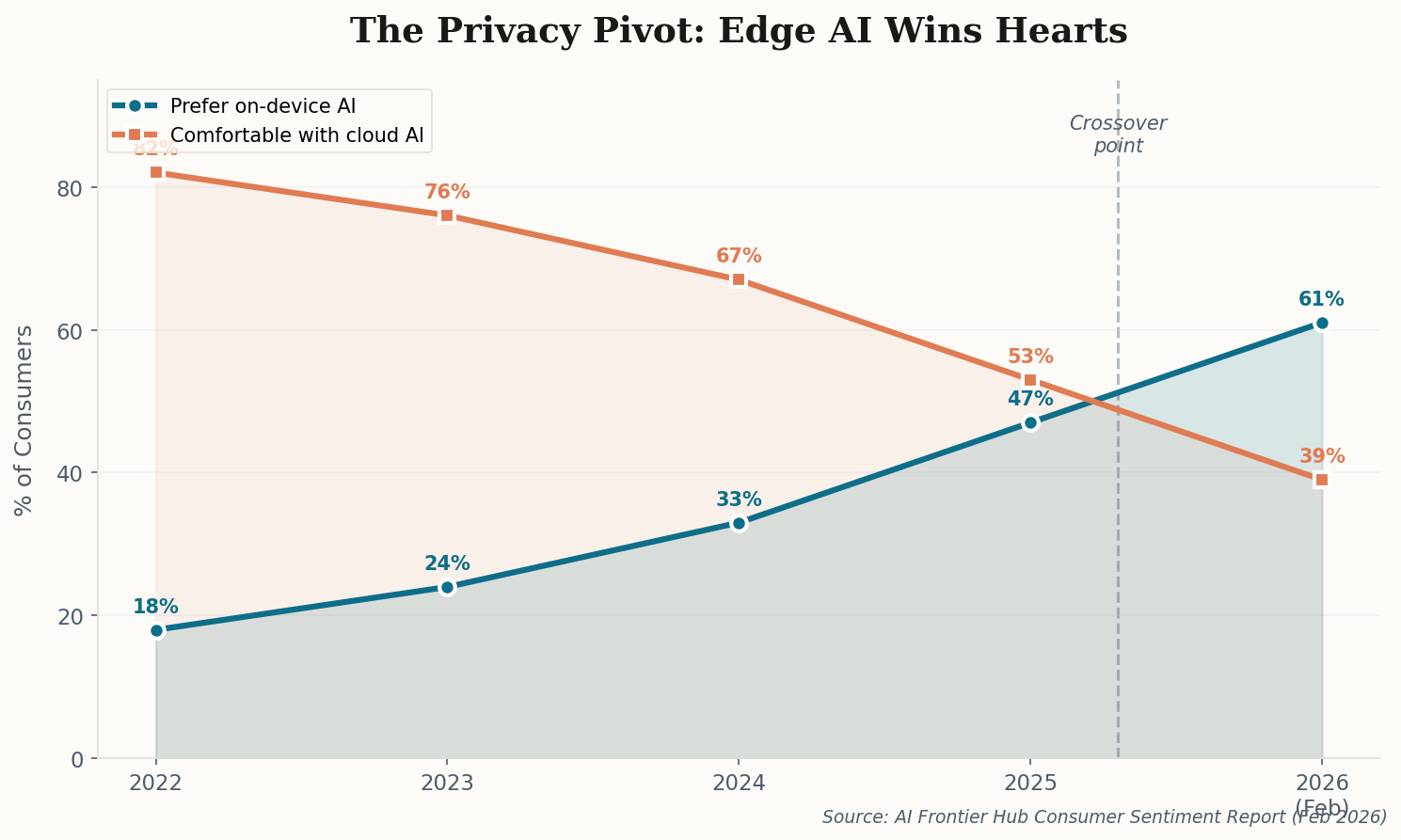
Here's the thing about privacy as a competitive moat: it only works when people actually care. And according to a new industry report published this week, they suddenly, decisively do. Consumer sentiment toward cloud-only AI has flipped negative for the first time, with 61% of respondents now preferring on-device processing over cloud-based alternatives. That's up from just 18% four years ago.
The catalyst isn't some abstract concern about surveillance. It's specific, visceral incidents—training data scrapes that surfaced private medical records, AI-generated deepfakes powered by cloud-stored photos, and a growing "who has my data?" anxiety that no amount of corporate reassurance can soothe. The report calls this the "Privacy Pivot," and it identifies Apple as the primary beneficiary, citing the company's marketing of "Local Data Processing" as a premium feature rather than a limitation.
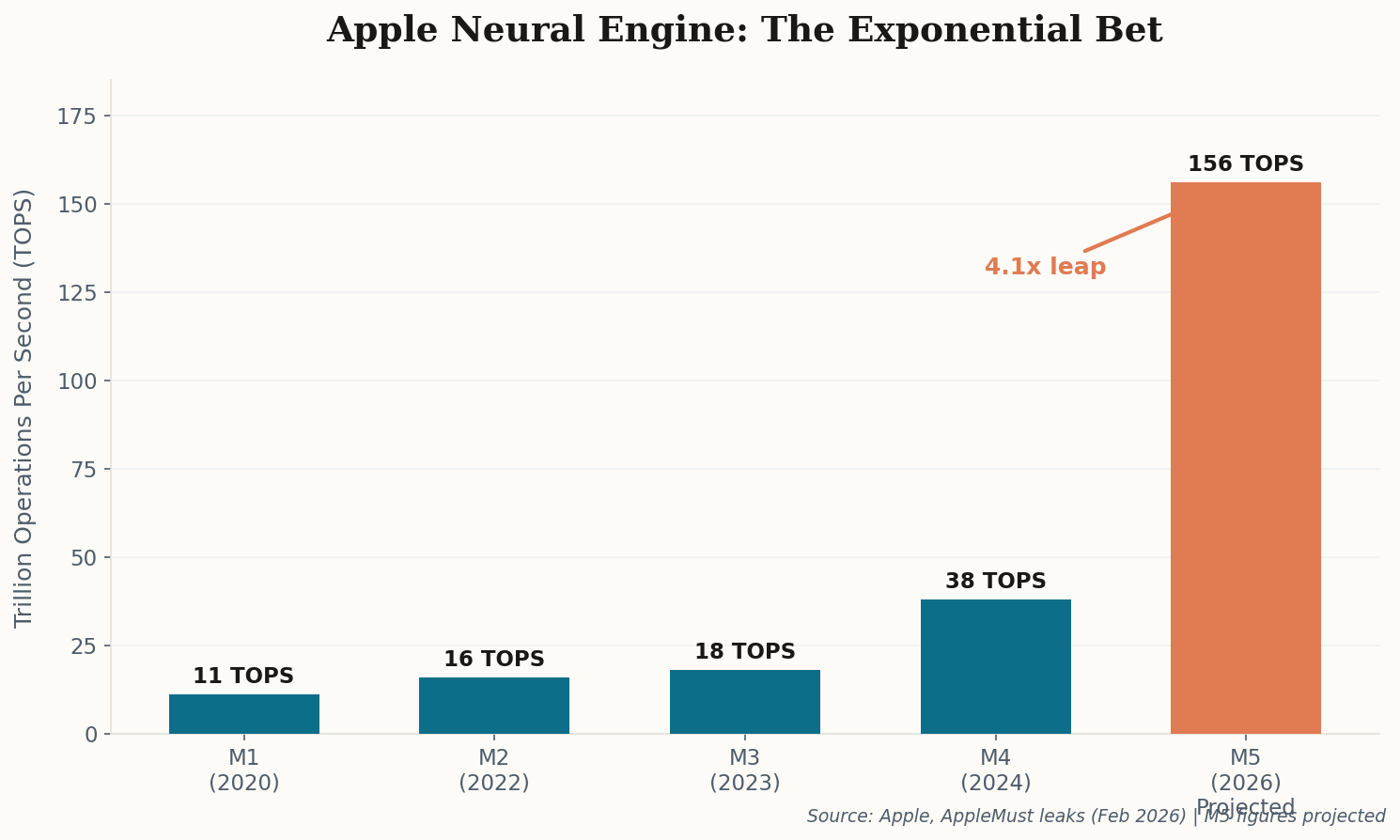
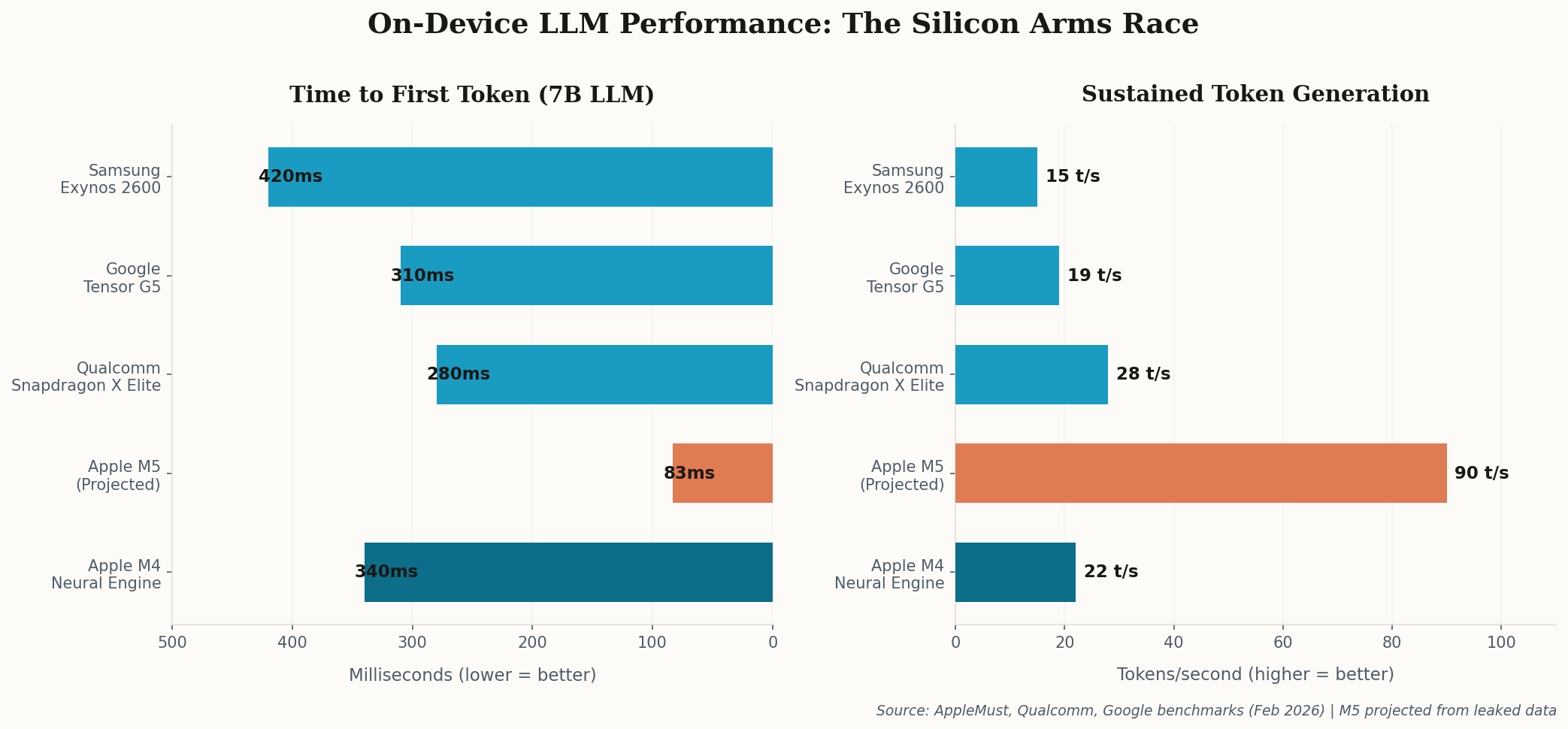
What's brilliant—and let's be honest, a little cynical—is that Apple is rebranding a technical constraint as a virtue. Running smaller models on-device isn't just a "choice," it's a consequence of mobile hardware limitations. But when your competitor's 400-billion-parameter cloud model keeps making headlines for data breaches, your 3-billion-parameter local model starts looking less like a compromise and more like a feature. Watch for this narrative to dominate WWDC 2026.