The Brain Gets a Memory: Opus 4.6 Goes All-In on Agentic RAG

Here's the tell that RAG isn't dead: Anthropic just spent considerable engineering effort making its flagship model better at it. Claude Opus 4.6, now generally available on Azure Databricks, is explicitly tuned for "Agentic RAG" workflows—the model doesn't just consume retrieved documents, it reasons about whether the retrieval was good enough, requests more context when it isn't, and cross-validates conflicting sources before answering.
The early numbers are striking: a 40% reduction in reasoning errors when synthesizing conflicting information from retrieved documents. That's not an incremental improvement. That's the difference between a system that confidently parrots the first result and one that actually thinks about what it read.
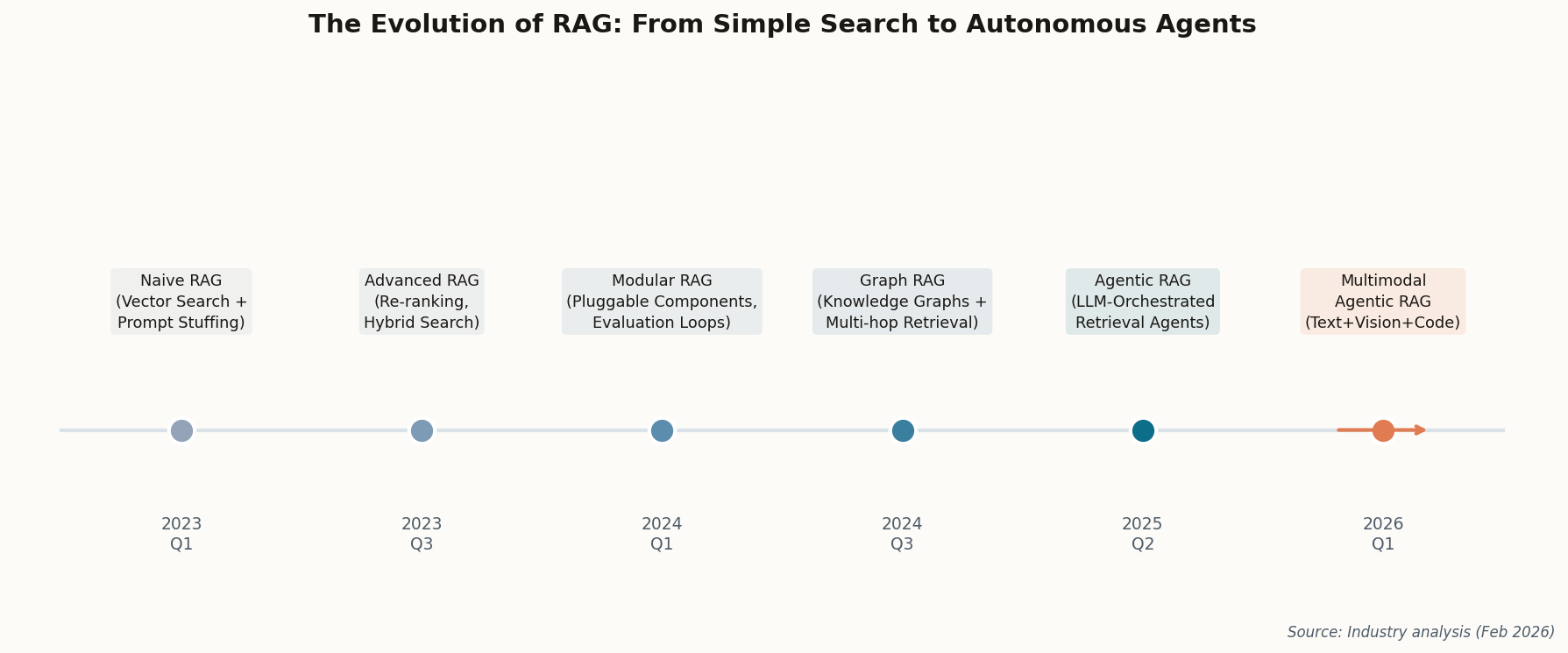
The shift here is architectural, not cosmetic. We're moving from "chat with your documents" (the 2023 pitch that launched a thousand failed demos) to autonomous agents that treat retrieval as one tool among many. The LLM decides when to retrieve, what to retrieve, and whether to trust what came back. If RAG were truly dead, the most capable model lab in the world wouldn't be optimizing for it. They'd be optimizing around it.