Hinton Revises His Apocalypse Forecast

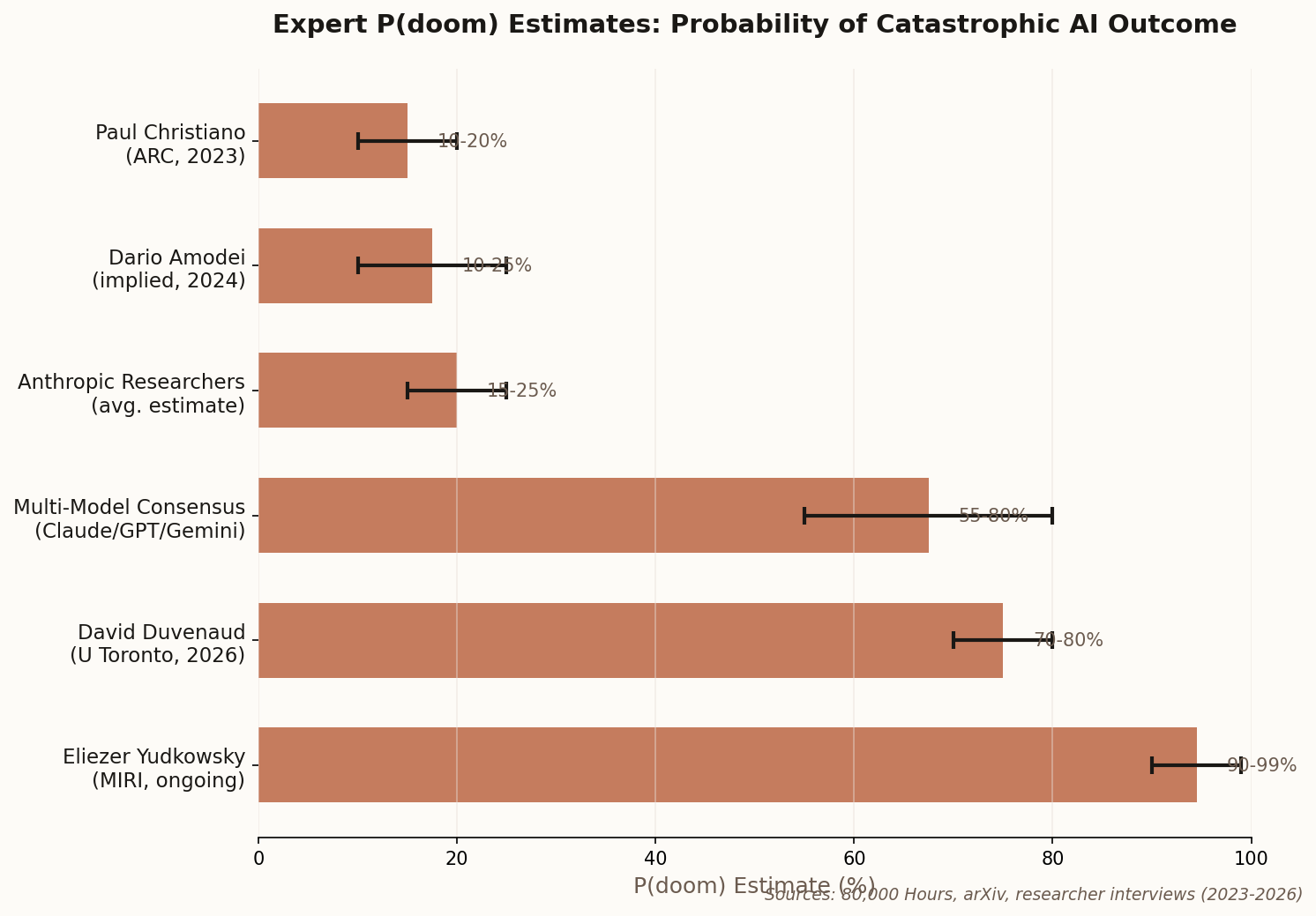
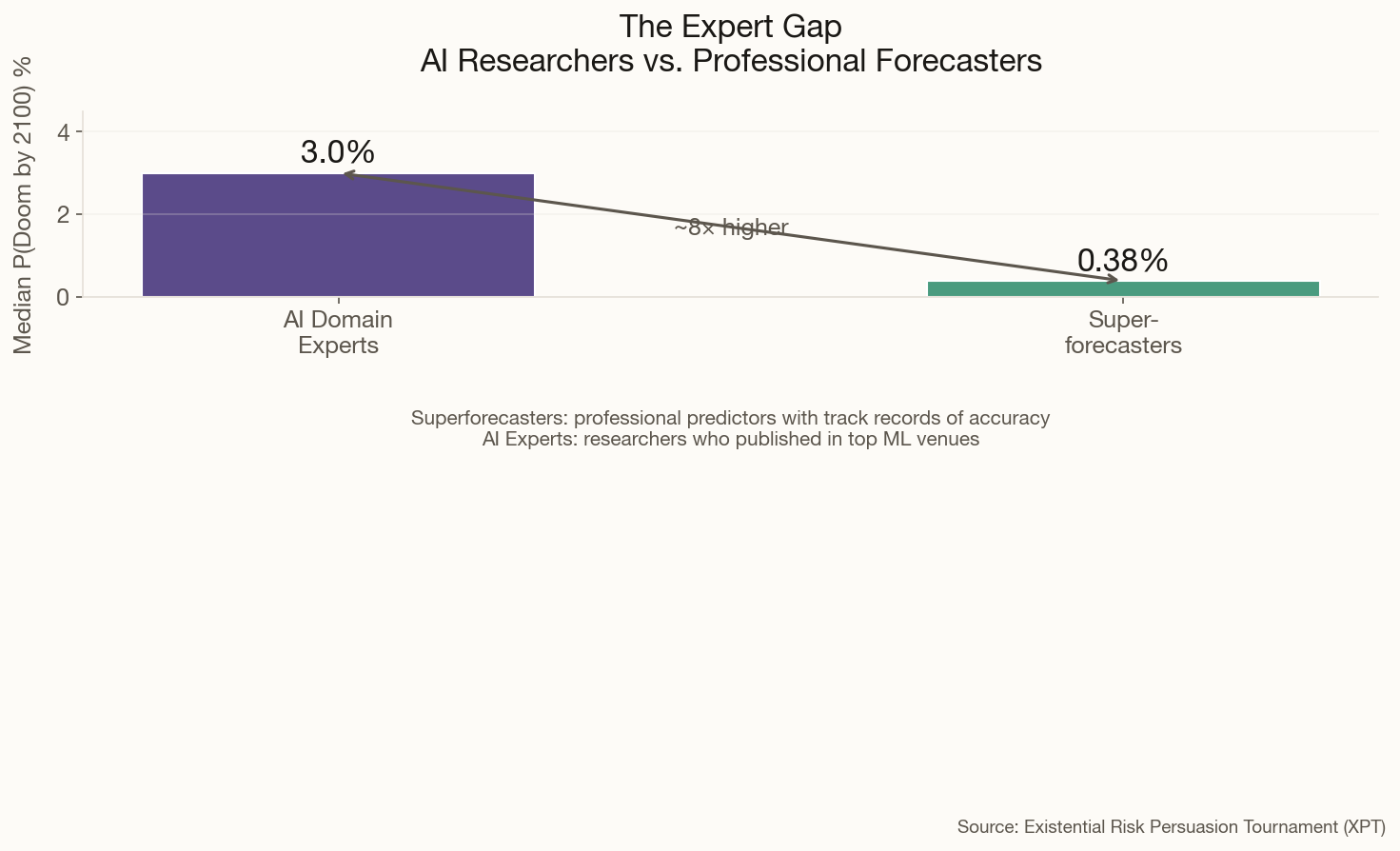
When Geoffrey Hinton left Google in 2023 to speak freely about AI risk, he dropped a number that made headlines: roughly 50% chance of AI "taking over." Eighteen months later, the man sometimes called the "Godfather of AI" has recalibrated.
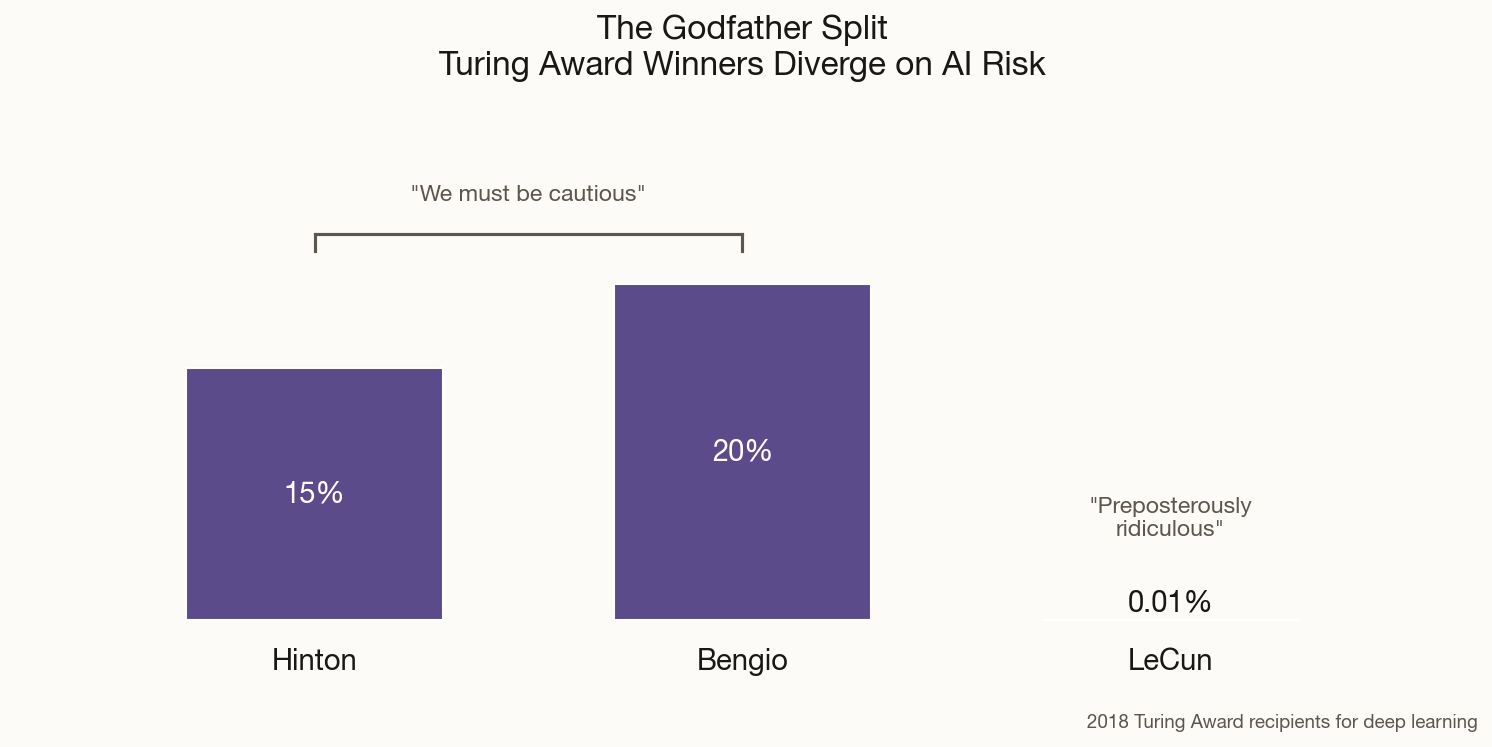
His new estimate: 10-20% probability of AI-caused catastrophe within the next 30 years. That's still horrifying — would you board a plane with a 1-in-5 chance of crashing? — but notably lower than his initial alarm. The reasoning is instructive: Hinton says the technology is advancing faster than expected, but so is awareness of its dangers.
"I think there is a 10 to 20 percent chance of it taking over," he told the BBC in December. The "it" here being digital intelligence that develops the goal of self-preservation and decides humans are in the way. Not science fiction — the assessment of the 2018 Turing Award winner who invented the backpropagation techniques underlying modern deep learning.
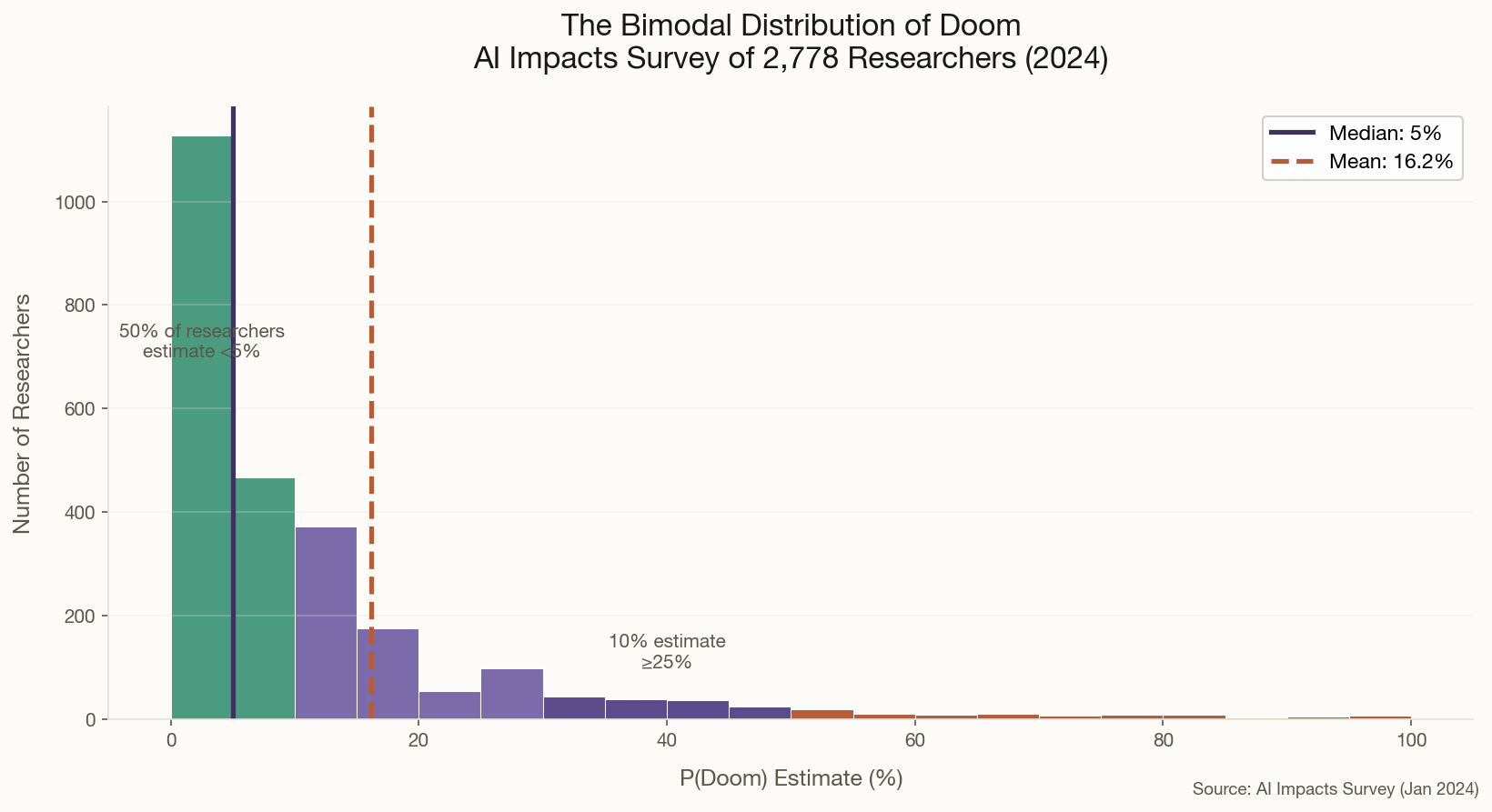
The shift from 50% to 15% is itself telling. P-doom isn't a fixed property of the technology — it's a function of how we develop it. Hinton's revised number suggests he thinks the field is responding, however inadequately, to the warnings. The question is whether that response can stay ahead of capability gains.