Andrej Karpathy Trains a ChatGPT Clone for $100

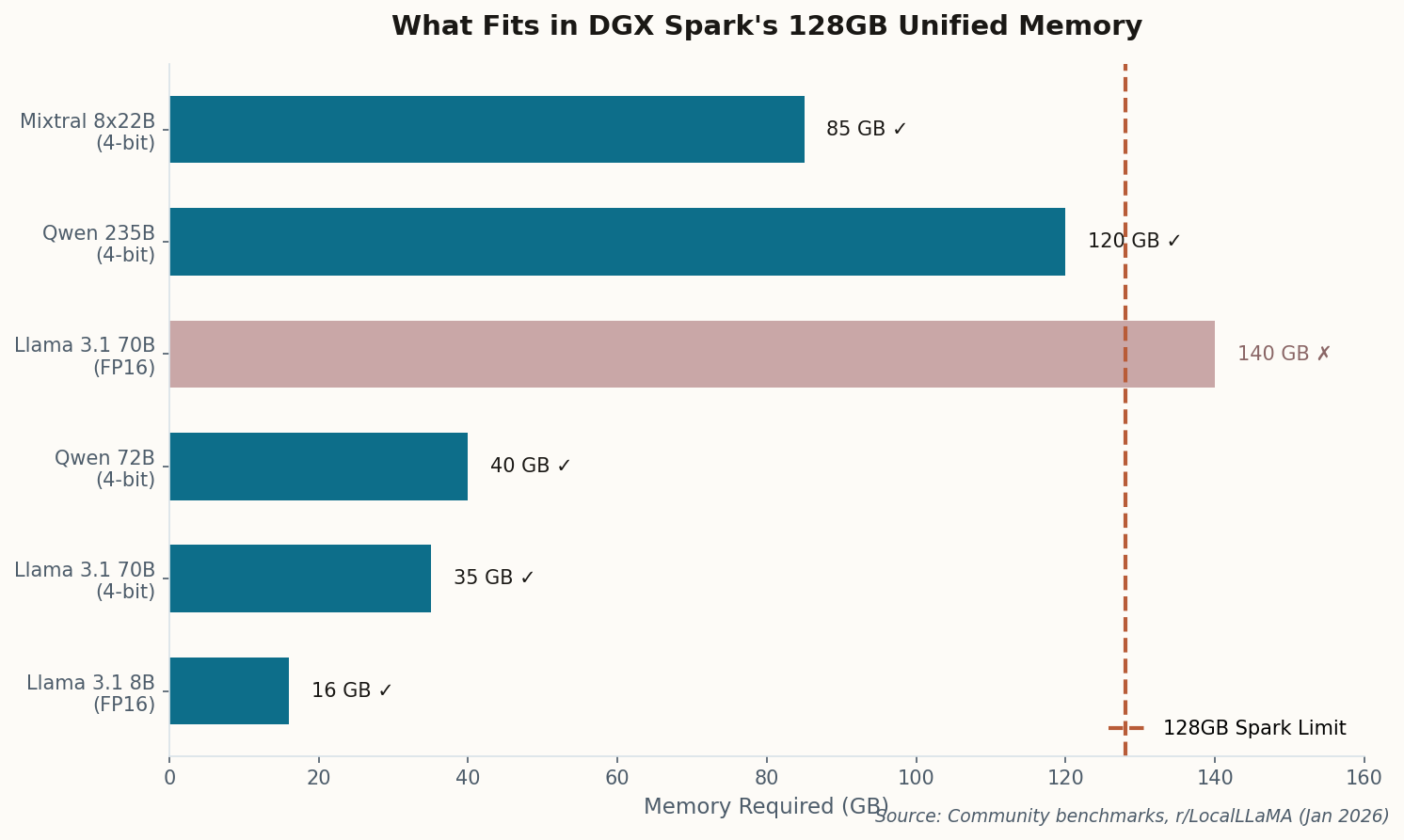
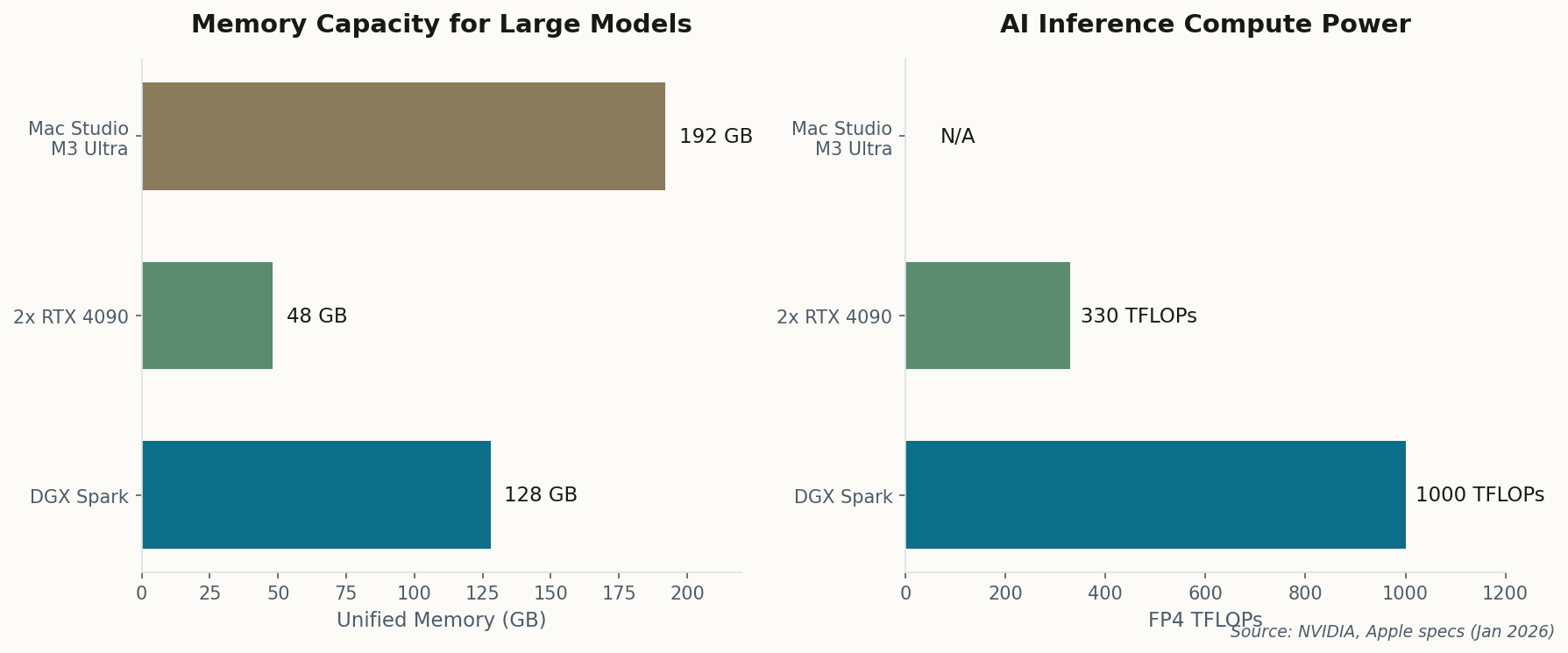
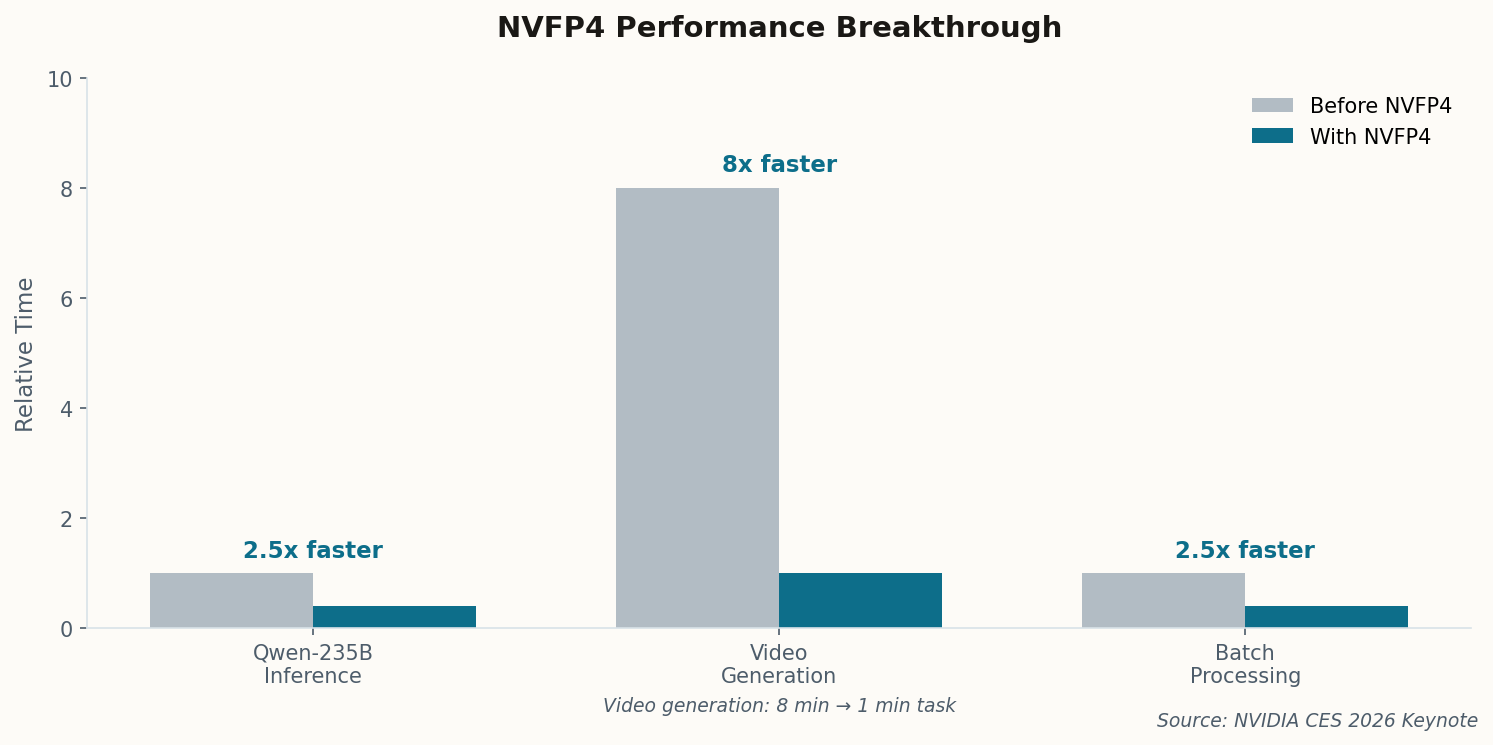
When Andrej Karpathy posts a project, the AI community pays attention. His latest experiment cuts to the heart of what DGX Spark actually means: he trained a functional, ChatGPT-style language model entirely on one box, for about $100 in electricity.
The implications are harder to ignore than the specs. This isn't running inference on someone else's model—it's training from scratch. Karpathy released the full stack: training code, inference server, and a web UI. Everything runs locally. No cloud. No API keys. No monthly bills.
"The barrier to entry for training your own specialized models has never been this low."
The project immediately spawned forks. Researchers are adapting it for domain-specific models. Hobbyists are experimenting with fine-tuning variants. The Spark isn't just democratizing inference—it's making training accessible to anyone with the skill to use it and a few hundred dollars for power.
What this signals: the era of "API-only" AI development has a serious competitor. If you can train a useful model at home, the economics of building AI applications shift dramatically.