Two Million Tokens Changed Everything
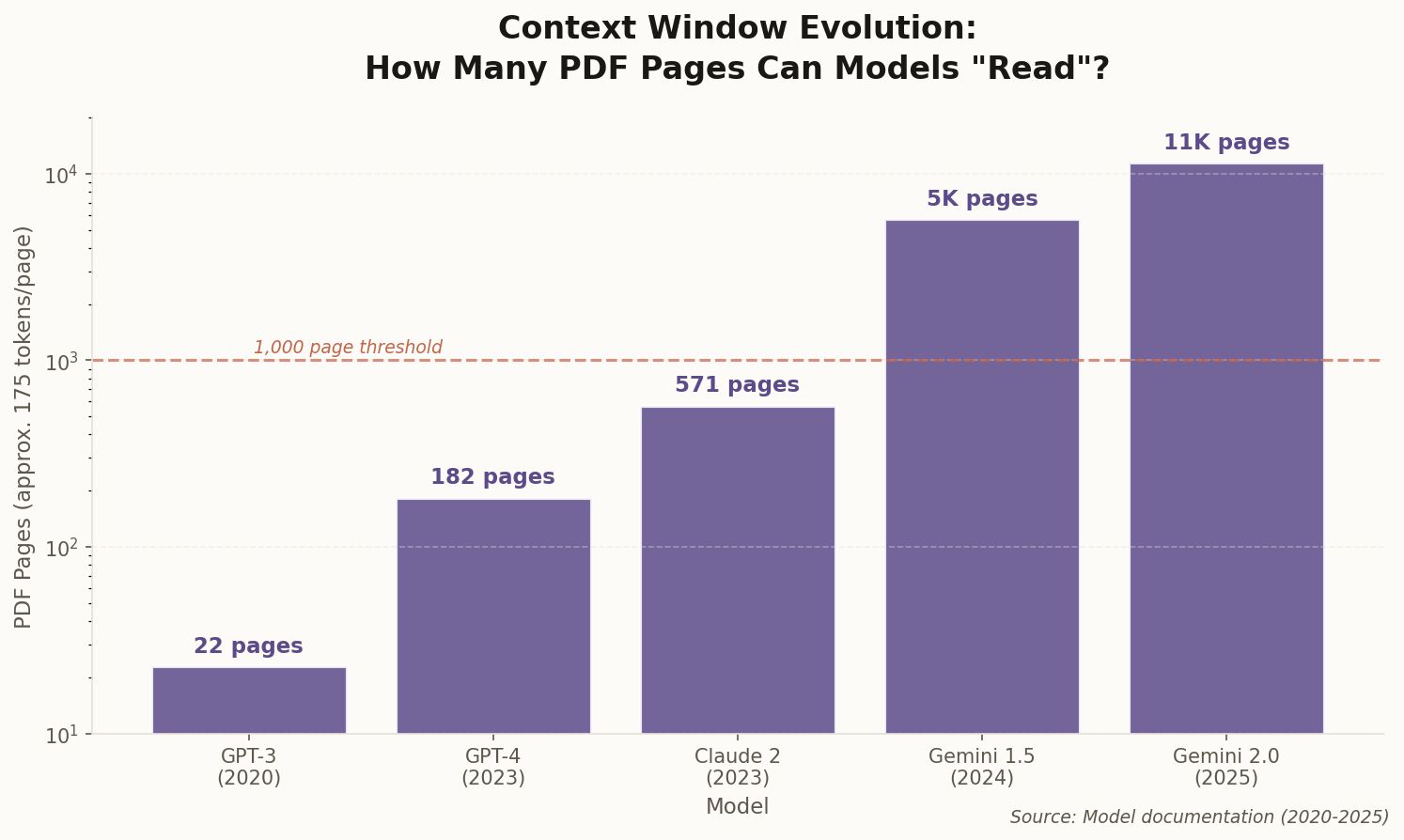
The math used to be brutal. A typical enterprise PDF clocks in around 175 tokens per page. Your 1,000-page annual report? That's 175,000 tokens minimum. Two years ago, you'd need to build elaborate chunking pipelines, vector databases, and hope the retrieval system surfaced the right passages.
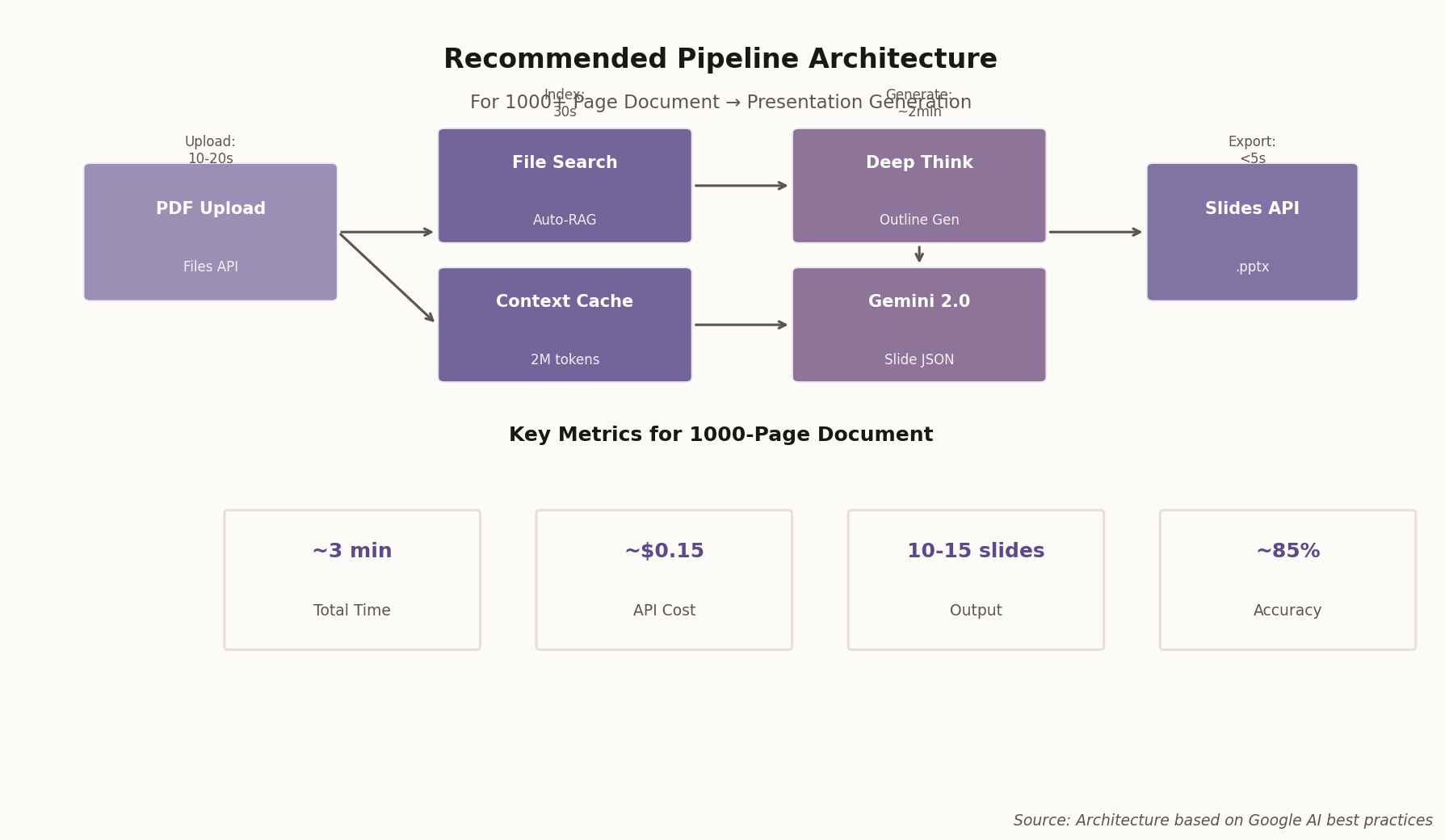
Then Google DeepMind shipped Gemini 2.0 with a 2-million-token context window. Suddenly, you can feed the model your entire document collection and ask it to synthesize a coherent presentation. No chunking. No retrieval. Just raw understanding.
The catch? Cost scales linearly with input tokens. Naively shoving a million tokens into every API call will bankrupt your startup before lunch. The real engineering challenge isn't capacity anymore—it's economics.