When Code Becomes Camera
Natural language prompts give you vibes. JSON gives you shots. That's the discovery emerging from SuperPrompt's developer community, who've cracked a surprising technique: structured data formats yield dramatically more predictable camera behavior than prose descriptions.
The secret lies in treating cinematographic parameters as instructions rather than suggestions. A prompt like "slow dolly with rack focus" might give you something approximating that movement—or might not. But {"movement": "dolly_in", "speed": "slow", "focus": "rack_focus_background"} forces the model to parse discrete, unambiguous commands. Think of it less like asking a cinematographer and more like programming a motion control rig.
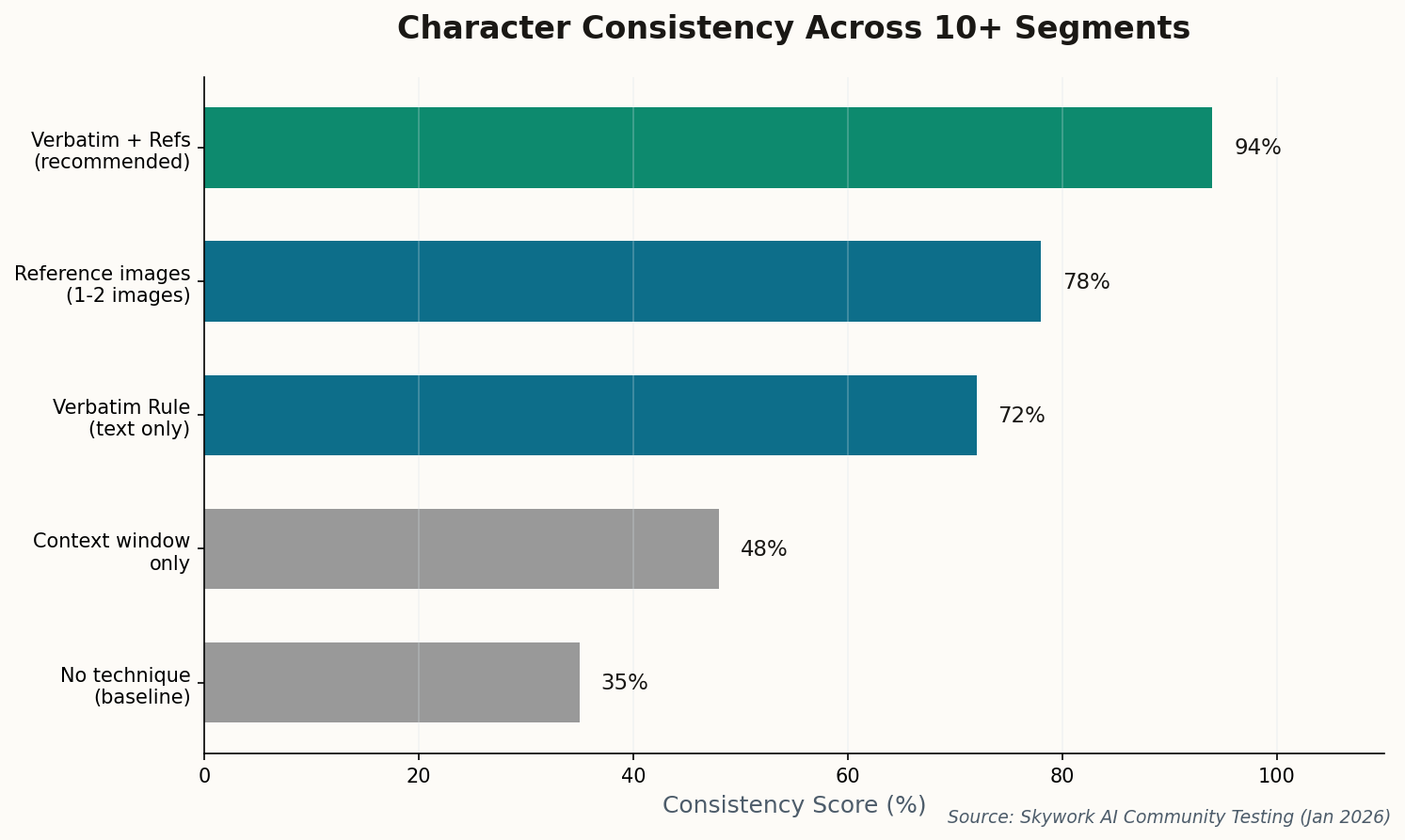
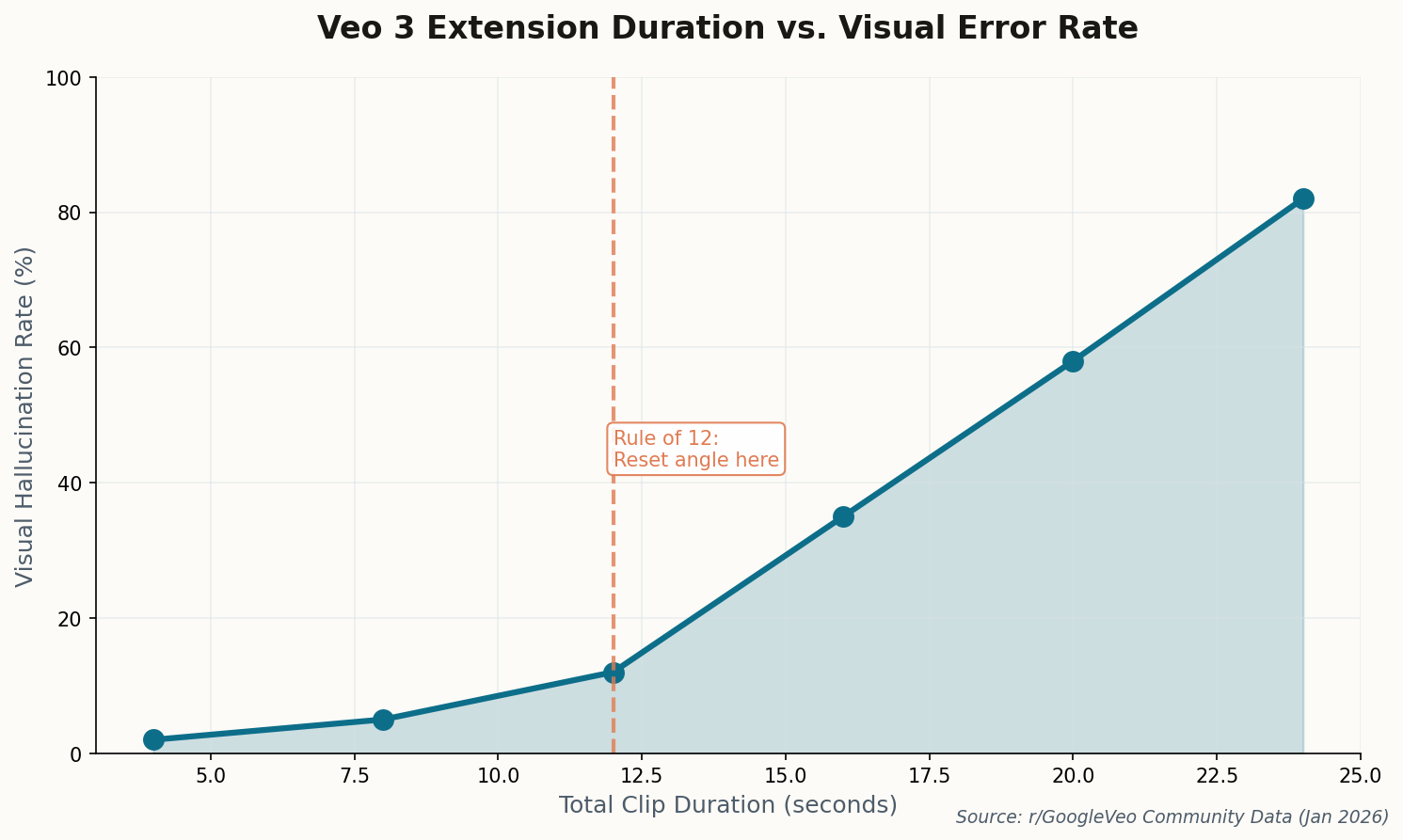
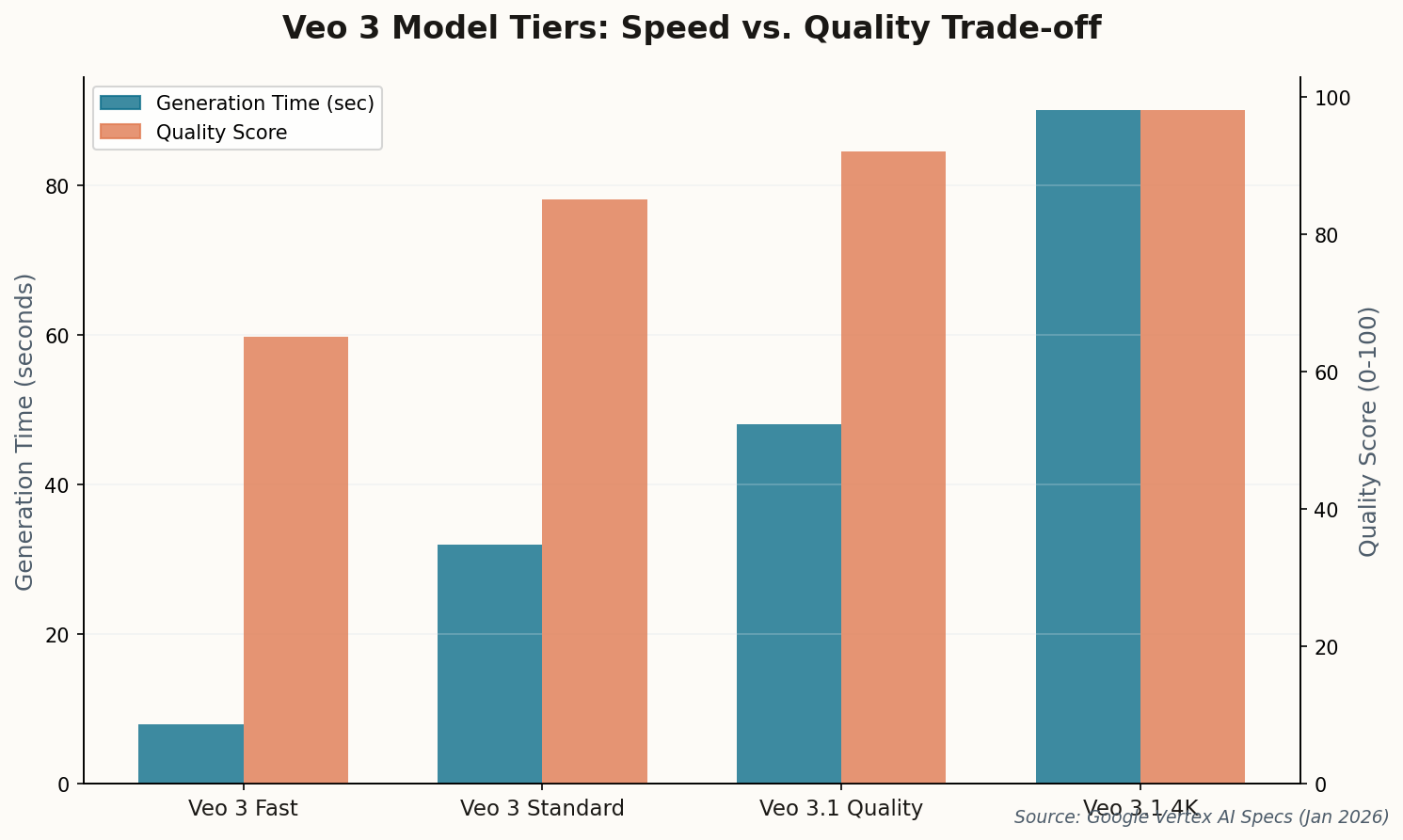
This matters for multi-segment work where shot-to-shot consistency is everything. If your first scene establishes a 50mm-equivalent field of view with a slow push, you need that exact vocabulary available for scene five. JSON isn't elegant, but it's reproducible. Professional filmmakers are finding that the twenty minutes spent learning the key vocabulary saves hours of regeneration later.
The technique also unlocks camera movements that natural language struggles to describe: "Dutch angle at 15 degrees, hold for 2 seconds, then level over 1.5 seconds." Try describing that precisely in English.