Data Science Agents Get Their Own Benchmark
Here's the uncomfortable truth about most AI benchmarks: they test whether a model can answer questions about data science, not whether it can actually do data science. DSAEval finally addresses this gap.
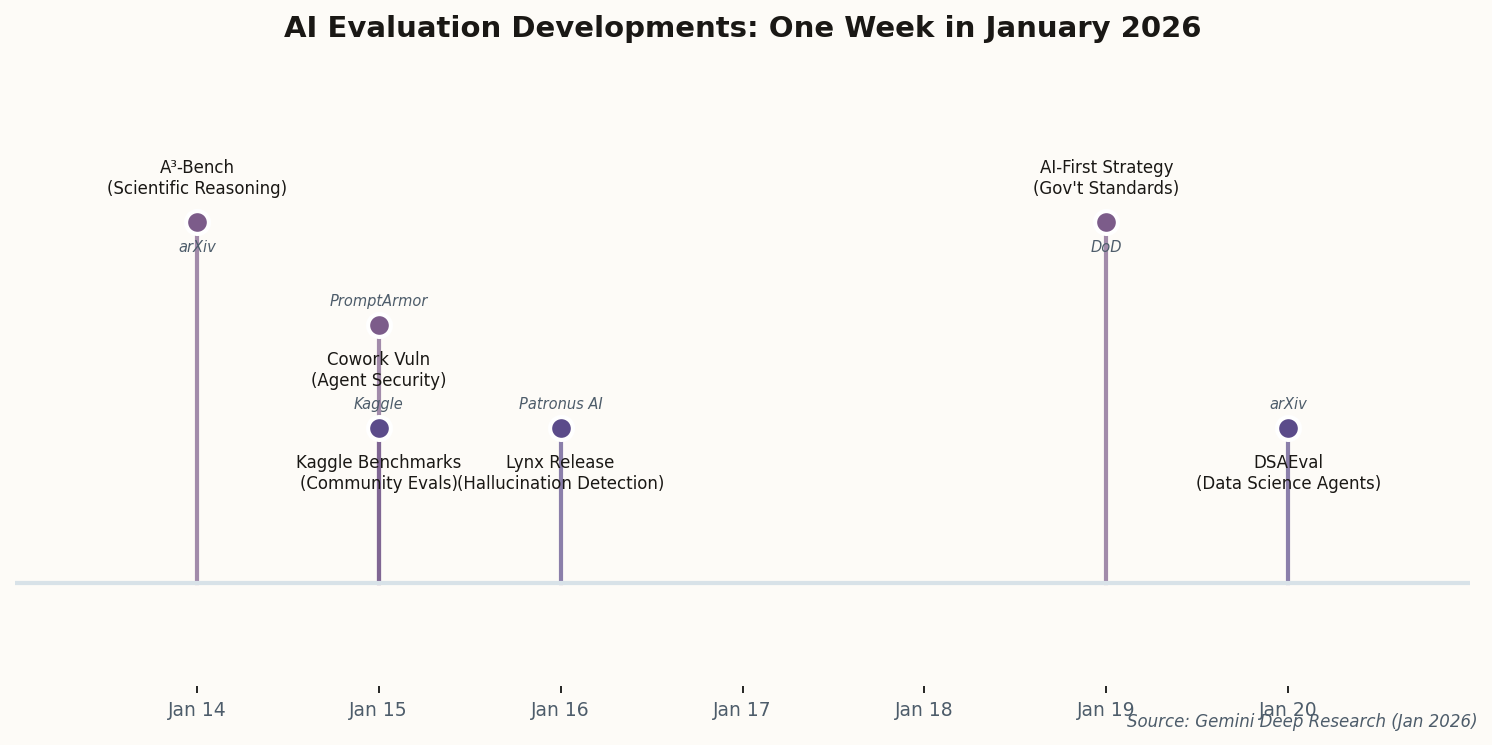
The new benchmark from arXiv researchers throws real-world data science problems at AI agents—messy datasets, ambiguous requirements, the need to write code, execute it, interpret results, and iterate. The kind of work that junior analysts spend their first two years learning.
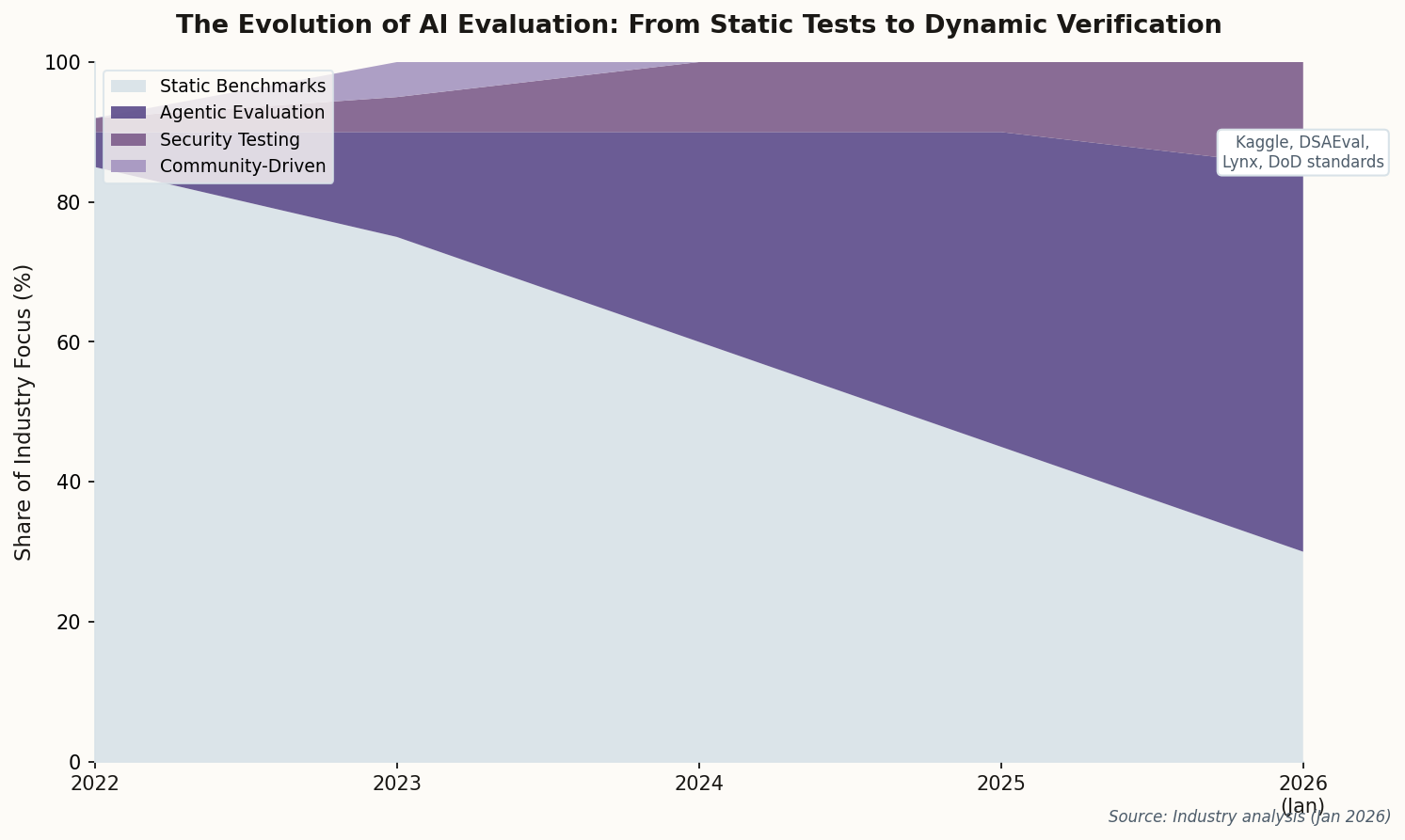
What makes DSAEval interesting isn't just the tasks—it's the evaluation criteria. Rather than checking if the agent produces "correct" code, it measures whether the agent's analysis would actually help a decision-maker. This is the maturation of agentic evaluation: testing functional capabilities in professional domains, not just text generation.
The so-what: If your organization is considering deploying AI for data analysis, DSAEval provides the first credible benchmark for comparing options. Expect vendors to start citing DSAEval scores within weeks.