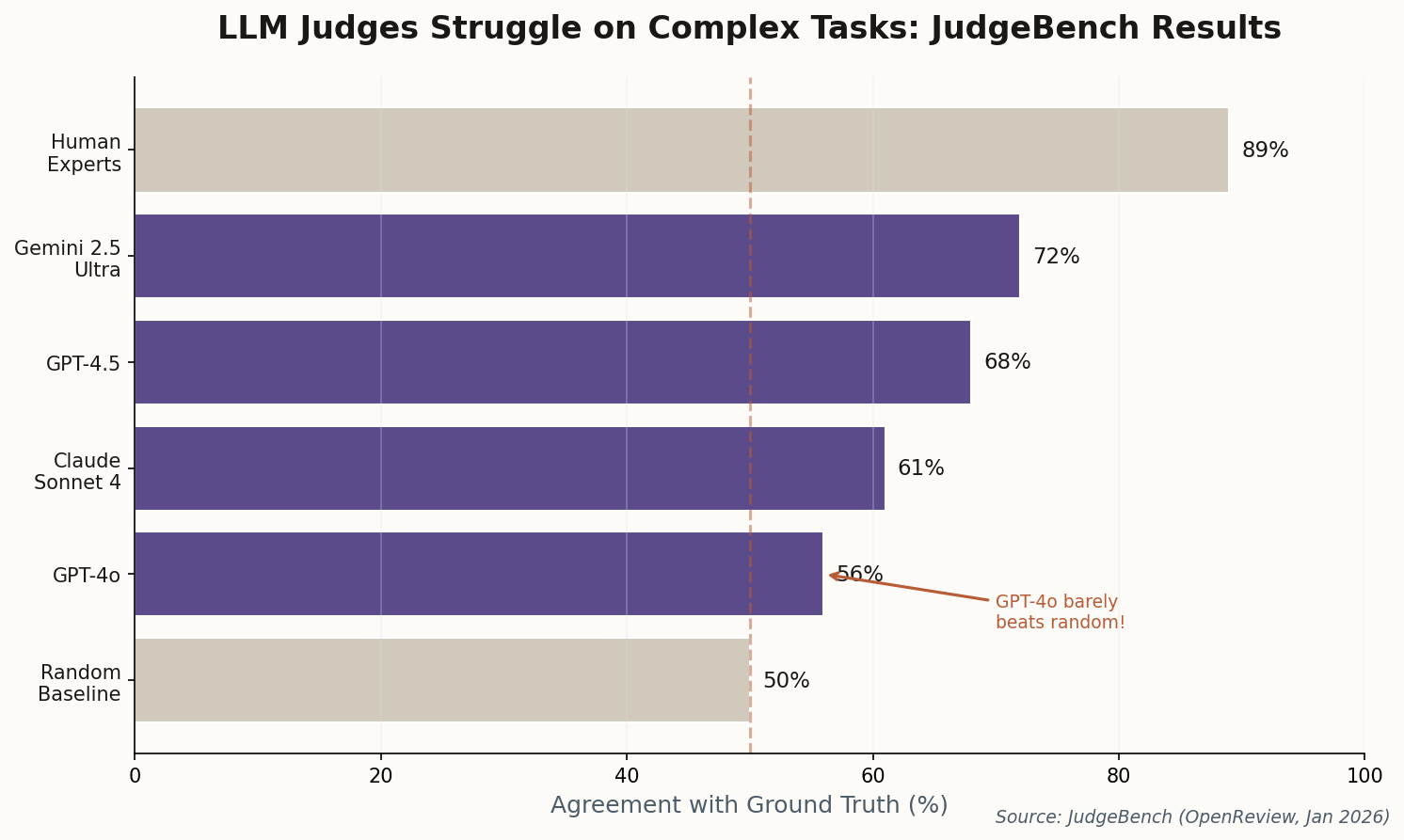
Reasoning Models Sweep the Leaderboards
The leaderboards have flipped. Mid-January updates to Hugging Face's Open LLM Leaderboard show a decisive pattern: "reasoning" models like OpenAI's o3-high and Google DeepMind's Gemini 3.0-Reason have displaced standard zero-shot models from the top five in coding and hard reasoning tasks.
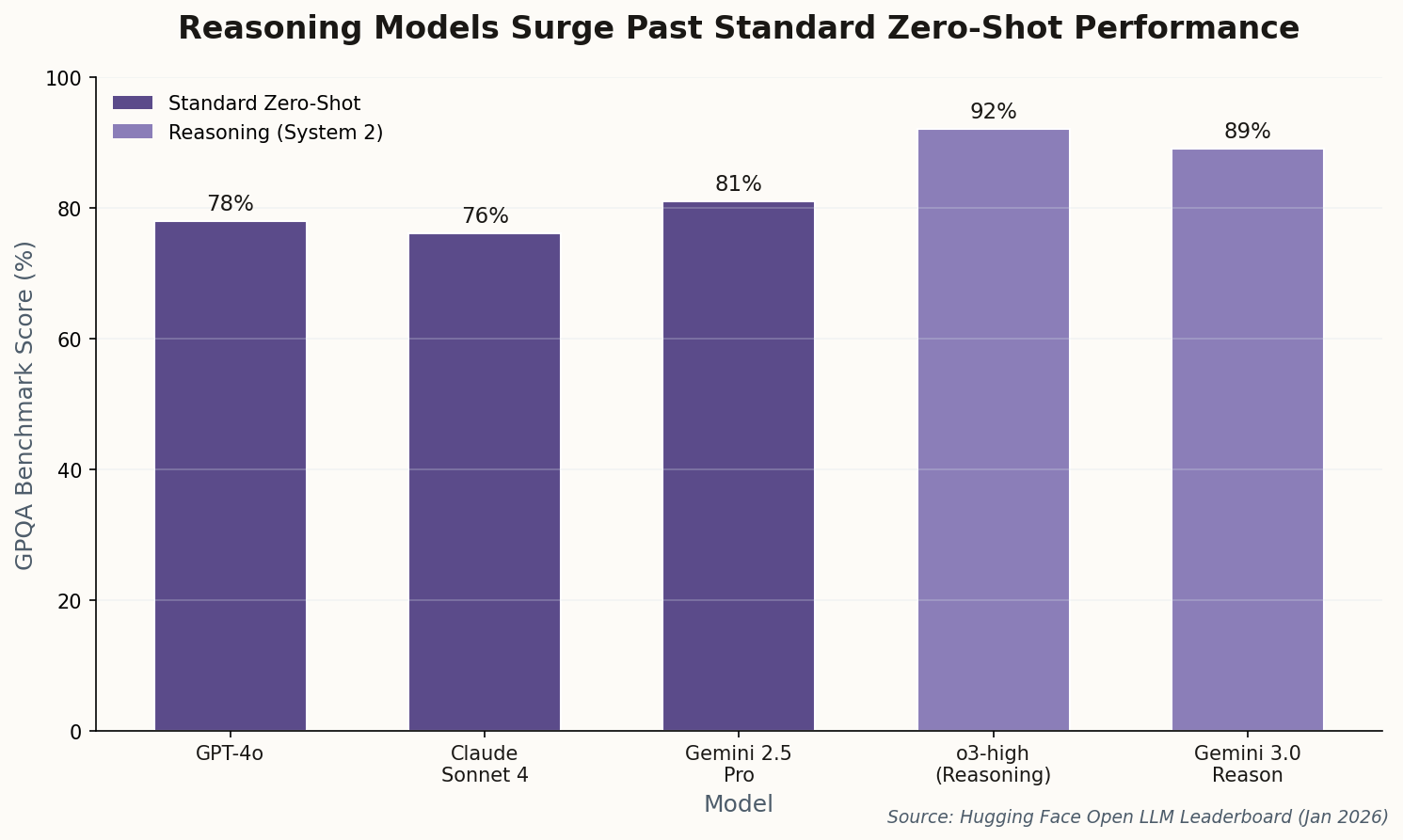
The secret sauce isn't architectural novelty—it's compute. These models use "Time-to-Thought," spending inference-time compute on multi-step deliberation before answering. Think of it as System 2 thinking for LLMs: slower, more deliberate, and dramatically more accurate on tasks that punish first-instinct responses.
The evaluation implications are profound. Standard benchmarks now need to account for "thinking time" to ensure fair comparisons. A model that takes 30 seconds to answer correctly might score higher than one that answers instantly but wrongly—but is that a fair comparison when your production system has a 500ms latency budget? The new frontier isn't just "what can this model do?" but "what can it do within the constraints you actually have?"