17 Experts Bet on 2026: Half a Work Week of AI Tasks, No Economic Miracle
Understanding AI assembled nine expert contributors to make 17 concrete predictions for 2026. The consensus: continued capability gains, but nothing that transforms the economy overnight.
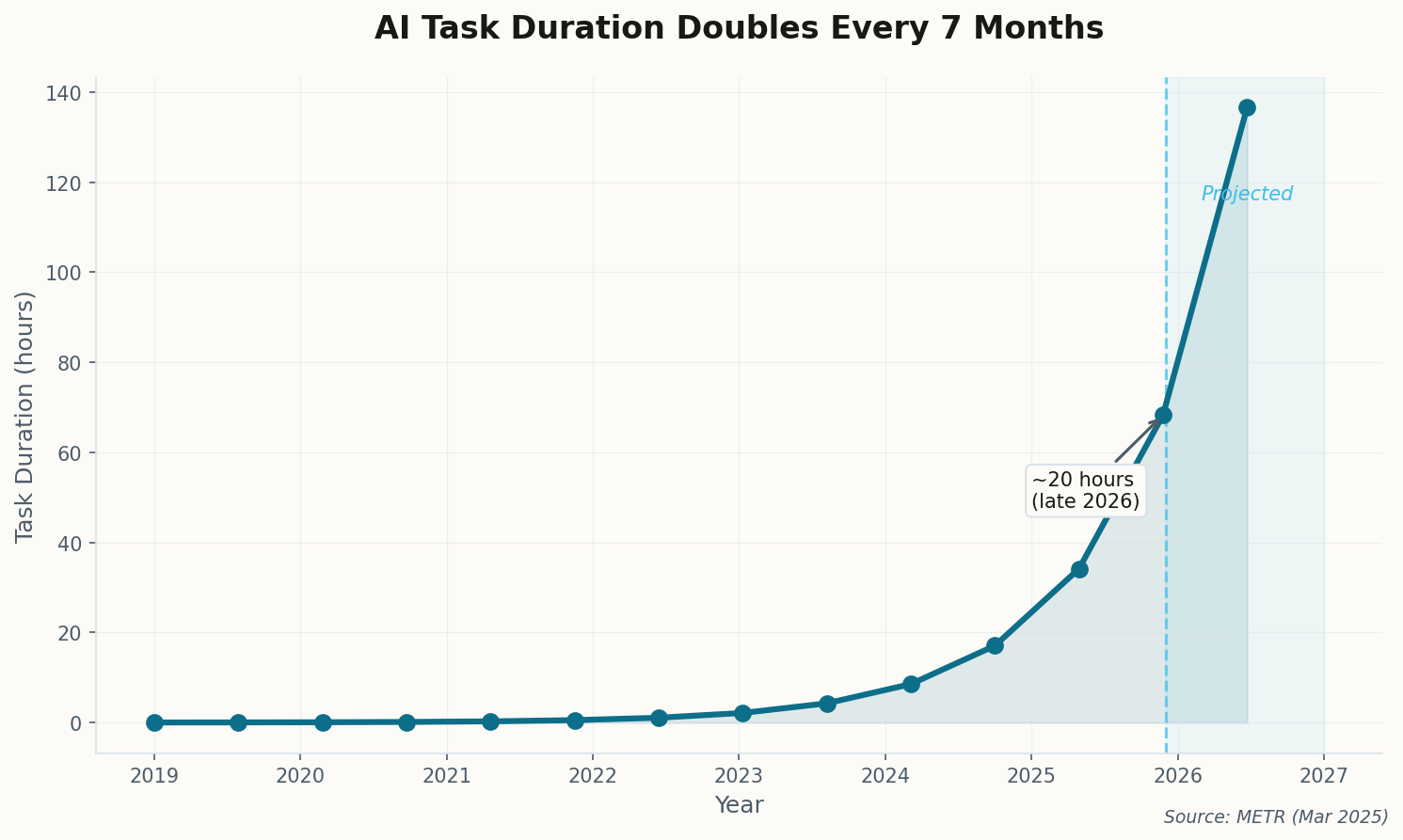
Timothy B. Lee predicts Big Tech capex will exceed $500 billion (75% confidence), with OpenAI hitting $30 billion revenue and Anthropic reaching $15 billion. Kai Williams forecasts AI completing 20-hour software tasks by year-end—half a human work week—at 55% confidence. But Lee directly challenges "fast takeoff" theories: he gives 90% odds that US GDP growth stays below 3.5%, far from the explosive growth some predict.
Other notable bets: context windows plateau around one million tokens (80%), a Chinese company surpasses Waymo in fleet size (55%), and Tesla launches truly driverless taxis (70%). James Grimmelmann predicts the legal free-for-all ends, with courts imposing serious financial consequences on AI companies.
The meta-lesson from 2025: Any advantage for an AI lab was temporary. Once one lab proved a capability, others quickly followed. The contributors expect this "fast-follower" dynamic to persist—meaning no one stays ahead for long.